I am running a radiation model with HB+. A heavy one, lots of context and 30000 calc points split into 2000 surfaces (hence 2000 analysis grids).
The setup was done quickly, but the radiance parameters are low (-ab forced to 1 with default “0” quality).
Yet, does this runtime seem normal to you (17 hours) ?
It seems to take an excessive amount of time after the cmd window closes (after step 3/3).
Its hard to qualify what is “excessive” without knowing the system specs. However, for the number of points that you mentioned, 17 hours on a Windows system operating on a single thread seems to be reasonable. I had tried something similar with 109,000 points last year. @mostapha talks about the details briefly in this video (its timestamped):
I ran the entire 109K points as a single calculation on a Microsoft Azure cloud machine(I think the spec was H16mr). The pre- and post-processing work were done in HB[+]. The calculations alone took around 9 hours.
Finally a word of caution about using an -ab 1 simulation. Rcontrib, the Radiance program used in Honeybee[+], is a very different animal compared to conventional Radiance programs implemented in Daysim. I would suggest comparing the ambient light in -ab 1 scenarios for rpict and rcontrib:
Rcontrib: https://www.ladybug.tools/radiance/image-parameters
Rpict: https://tt-acm.github.io/DesignExplorer/?ID=KeF5zn
An -ab 1 calculation in HB[+] will be more inaccurate than it would be in Honeybee/DIVA/Daysim. I would recommend at least -ab 3 (for better accuracy) or -ab 5 (for convergence).
I think most of the time currently is happening because how Honeybee[+] loads the results. Implementing the database should address this issue.
I think @sarith’s comment here refers to illuminance/luminance studies. I would say it’s not as critical in a radiation study, unless you have highly reflective surfaces.
Yup, I was talking about illuminance. It slipped by me that this is a radiation study. On a related note, has anyone done a comparison between gencumulative sky and our version here?
loading the results does take a lot of time. I did a couple project tests, and it takes about 40 mins to run the simulation, but it takes ~30 mins to load back to gh.
It’s mostly Grasshopper than Honeybee[+] itself. If you run the same script outside Grasshopper it should run much faster. Database implementation will put an end on this issue!
There is another issue that stops me to run the regular project study instead of box model with HB+ is the memory issue. I understand that puts all raw data in memory increases the post processing speed, but it eats a lot memories and reduces GH interface’s performance.
I am thinking probably we can post process some standard annual metrics outside of gh, and release the memory after saved the result file (or database), and GH just needs to load the final results for the most cases.
I am not convinced that Gh can even handle massive projects with 50K or more points. Part of the bottleneck is also the issue with the final matrix, where it is something like 50,000 * 3000 suns with 8 digit floating point numbers. Even with a 260GB RAM machine, we still couldnt fit the memory to run that calc. Is the raditiation calc just 145 patch calcs?
I will try to do the comparison between gencumulativesky and the HB+ recipe.
Two more questions:
does the database implementation look like a 2018 Q2/Q3 release or should we wait a bit longer for this nice feature to be available ?
I am sorry to ask this but unfortunately it seems hard atm for HB+ to compete with the old Ladybug radiation on a large scale project. It is a shame because the post-process opportunities and accuracy look far greater to me with HB+ but the time to load (or even re-load existing results) is currently prohibitive.
would I save any time if I loaded my 30000 calc points as 1 single analysis grid (flatten after meshing) ?
Does this also have an impact on the results at all ? I am thinking (without fully mastering the background calcs) raytracing is stochastic per analysis grid or for the entire scene ?
Say I have a building with 10 floors with 2 zones on each floor.
Would you recommend using one single (flatten) analysis grid or several (2 x 10 = 20) analysis grids ?
Does it influence the results at all ?
It will not if you are using the same geometry for all the runs. However, if you use a single grid for multiple rooms, you might have to put in some extra work while post processing the results (to calculate annual metrics and such).
It has been proved that my predictions for release dates for futures are doomed to failure for most of the time but assuming no surprise I’m planning to finish it before the end of August!
That is how Honeybee[+] does it currently. Before running the simulation Honeybee[+] merges all the points into a single point input file and then separates them when it imports the results for post-processing.
Thanks @mostapha, I am really looking forward to checking it out.
OK, thanks for the clarification. I should try at some point to make a comparison - loop through the analysis grids one by one with Ladybug Fly versus one single merged analysis grid.
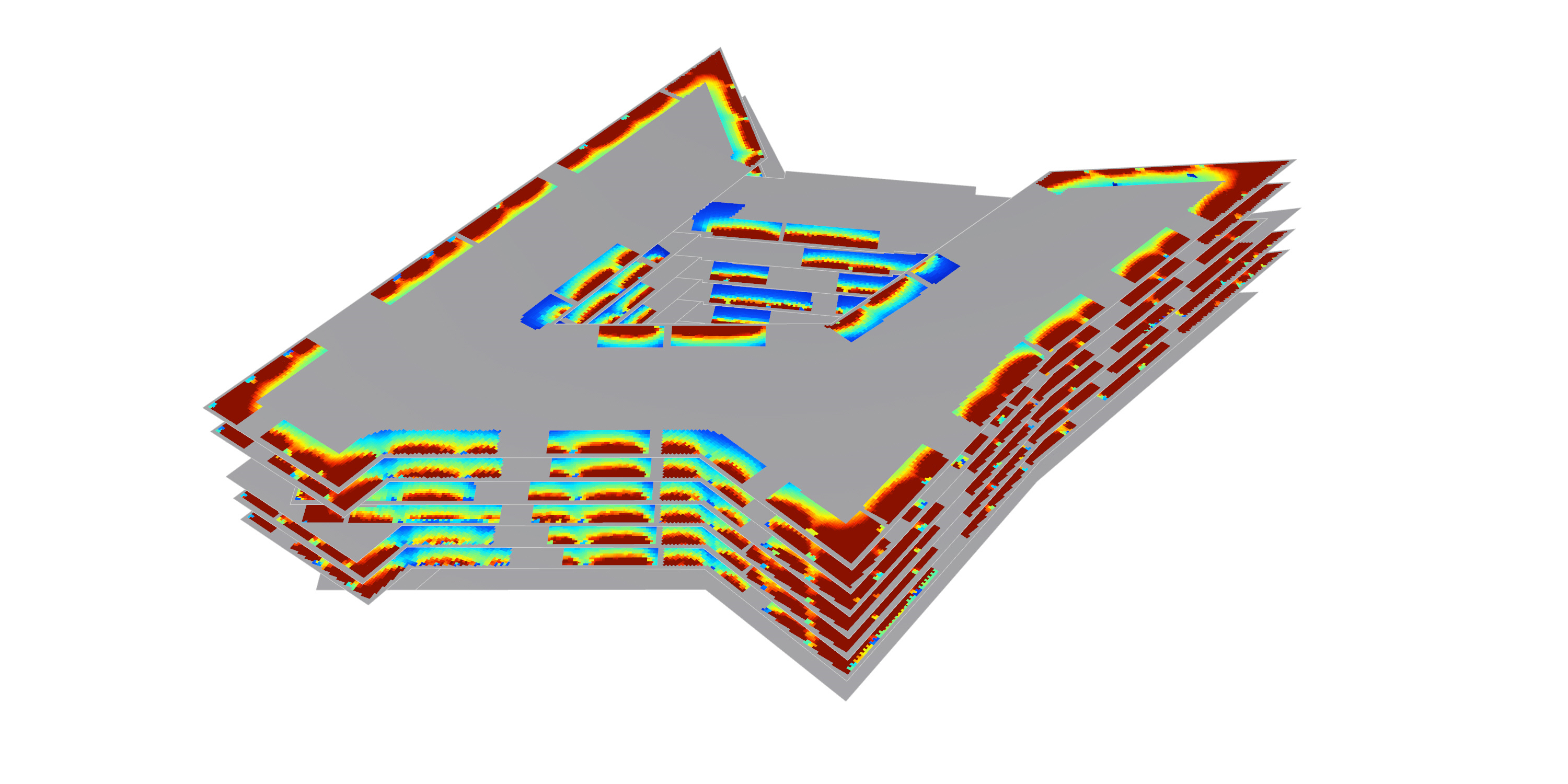
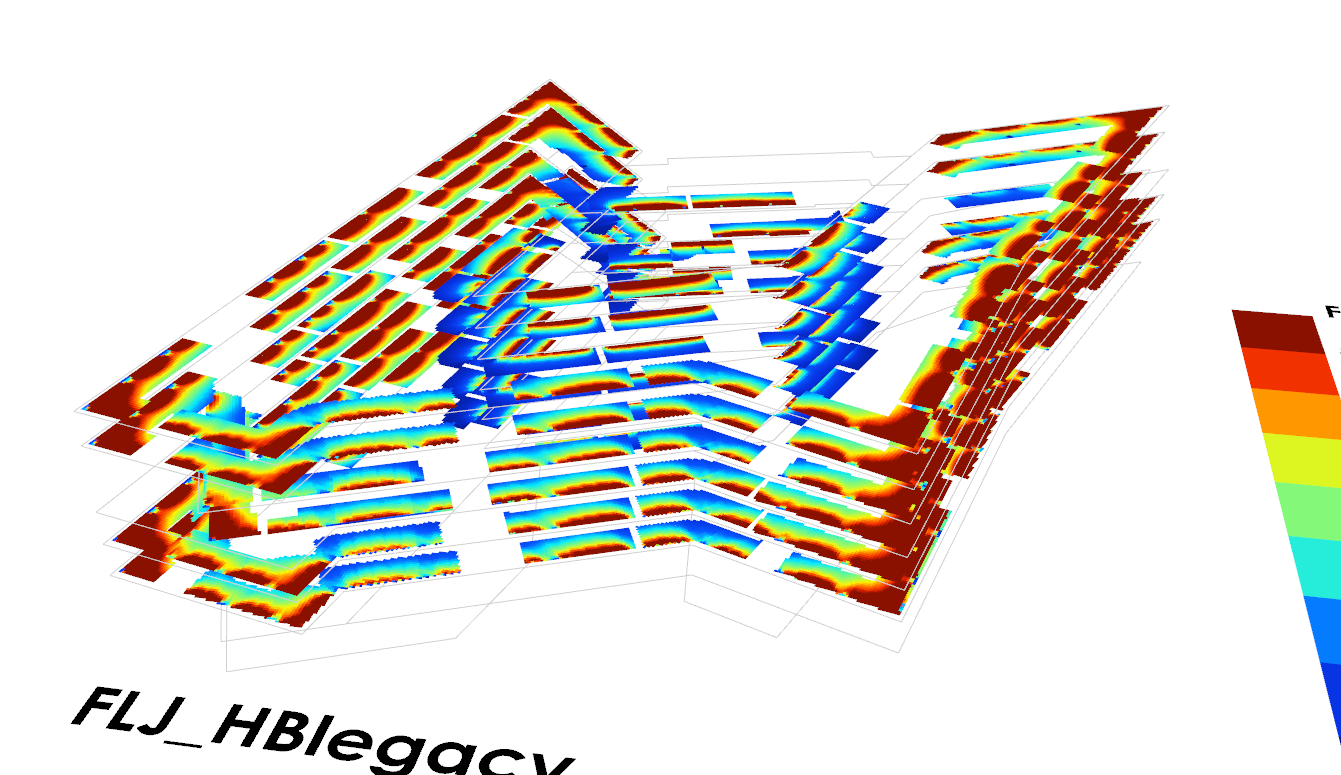
On a (slightly) separate topic, I’ll share a recent experience on running a heavy model.
A daylight factor analysis with HB+ (with the code modified to get float results rather than rounded values), run on an entire building at once (approx. 12,000m² of tested surfaces, 135,000 test points, 140 analysis grids)
Its worth checking if the numbers make sense or not (in real world terms). Your ambient divisions appear to be too low for a space of that size.
A “quick” test would to be cut down the number of points by 20 times (by using higher grid spacing) and then do a parametric run with increasing ambient divisions (say -ad 4000 for one run, -ad 8000 for next…and set -lw as 1/ad each time so that the rays dont get killed off). If you see a wide variation in the results, then your ambient settings are too low.
The reds in your plots are mostly from direct sun, and that part is (mostly) accurate. Direct sun calculations are deterministic so one can be fairly certain about their precision.
thanks for this.
Unlike the first case I was querying about in this thread (an annual radiation study with DC), this analysis was actually a simple daylight factor. No sun and results making physical sense generally.
Sorry I should have made it clearer. Bbut I thought this feedback would fall under the topic “HB+ runtime for heavy models” since it’s a pretty big model (to me) aiming to explore DF% analyses with HB+ rather than the legacy plugins.
If I am correct, the DF recipe only uses rtrace, for which -ad set at 4096 is already quite high ?
Higher values of -ad (15000+) should apply to rtcontrib for multi-phase simulations only, am I right ?
I didn’t know the rule of of keeping -lw = 1/ad so thanks for this anyway !
I didnt read your last post carefully and thought that this was an annual calc, but yes, the daylight factor calculation in HB[+] also uses rtrace. I am not quite sure why this would be faster than the legacy version though (@mostapha ?) .
The reason for using the reciprocal value for limit weight (lw) applies for rcontrib based calculations only. The ambient caching algorithms implemented in standard radiance programs like rtrace and rpict are overridden in rcontrib (and by extension rfluxmtx), so the way to compensate for that is to use a higher ad value.
It should be the same. Nothing really has changed between the two.
On that note in Honeybee legacy I don’t really take advantage of sharing the ambient file between separate runs. I remember I tested it once and I faced some issues (which I don’t remember!) but that can be something to be implemented in Honeybee[+] for Windows.
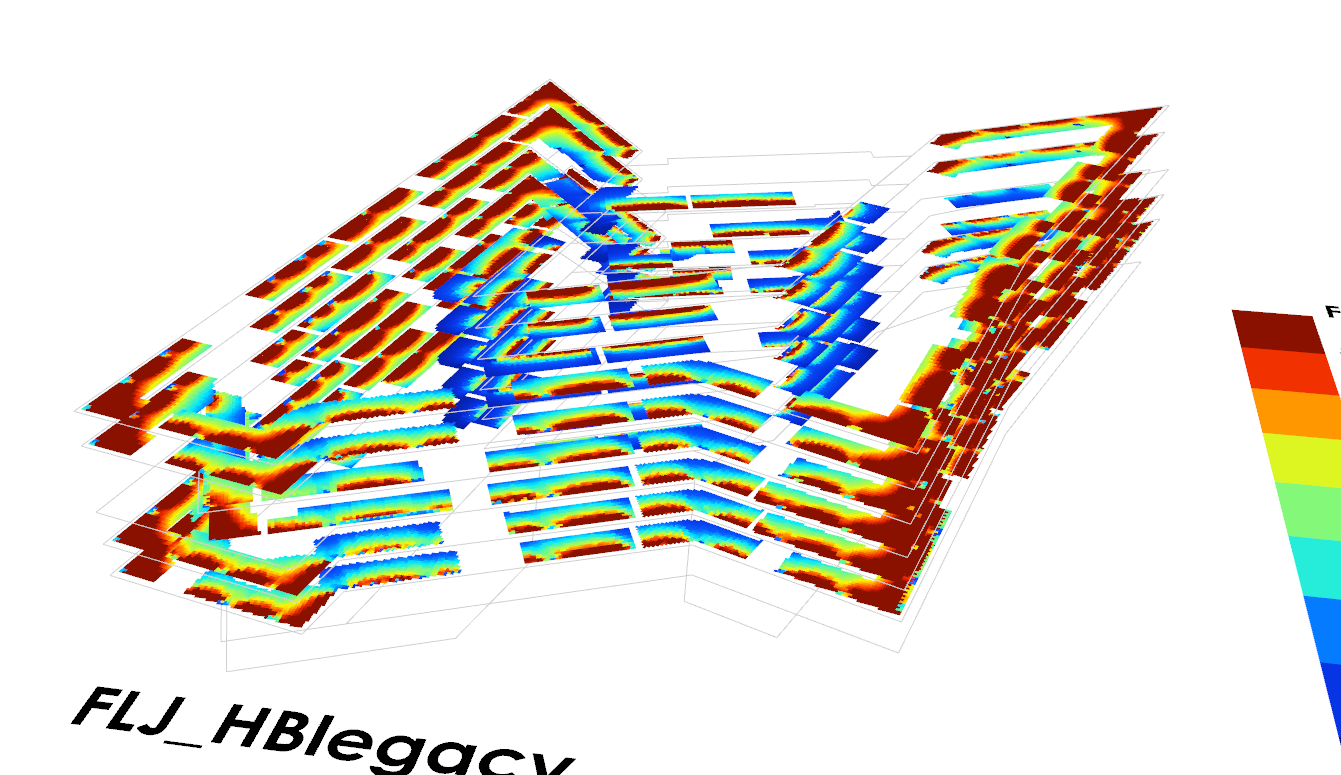
1 single grid will all test points flatten (135,000 test points) in HB+ = took 4 hours on one core
140 grids with 135,000 distributed amongst them in HB + = took 40 hours on one core (no surprise here, I simply used ladybug fly to calculate them one after the other, to see if that makes a difference)
1 single grid will all test points flatten (135,000 test points) in HB legacy = took 8.5 hours on 10 cores
I expected the runtime to be ~10 times less with HB legacy because I could split the calc between 10 cores.
I thought the radiance parameters (quality 2) would be the same : -lw 0.005 -dc 0.75 -ar 128 -ss 1.0 -dp 512 -dr 3 -dt 0.15 -ab 6 -as 4096 -ds 0.05 -aa 0.1 -lr 8 -ad 4096 -dj 1.0 -st 0.15
I think I figured why this wasn’t the case. There is an automated check on ambient settings withtin the HB legacy component which forced -ar to 300 (instead of 128). @mostapha, could you clarify why this is here, how to modify it and whether the plan is to implement it in HB+ too ?
I am not against it at all, but I’d be curious to understand how this is done.
The results do look a bit smoother with HB legacy, although for the metric I calculated this didn’t seem to make such a significant difference.