Hi
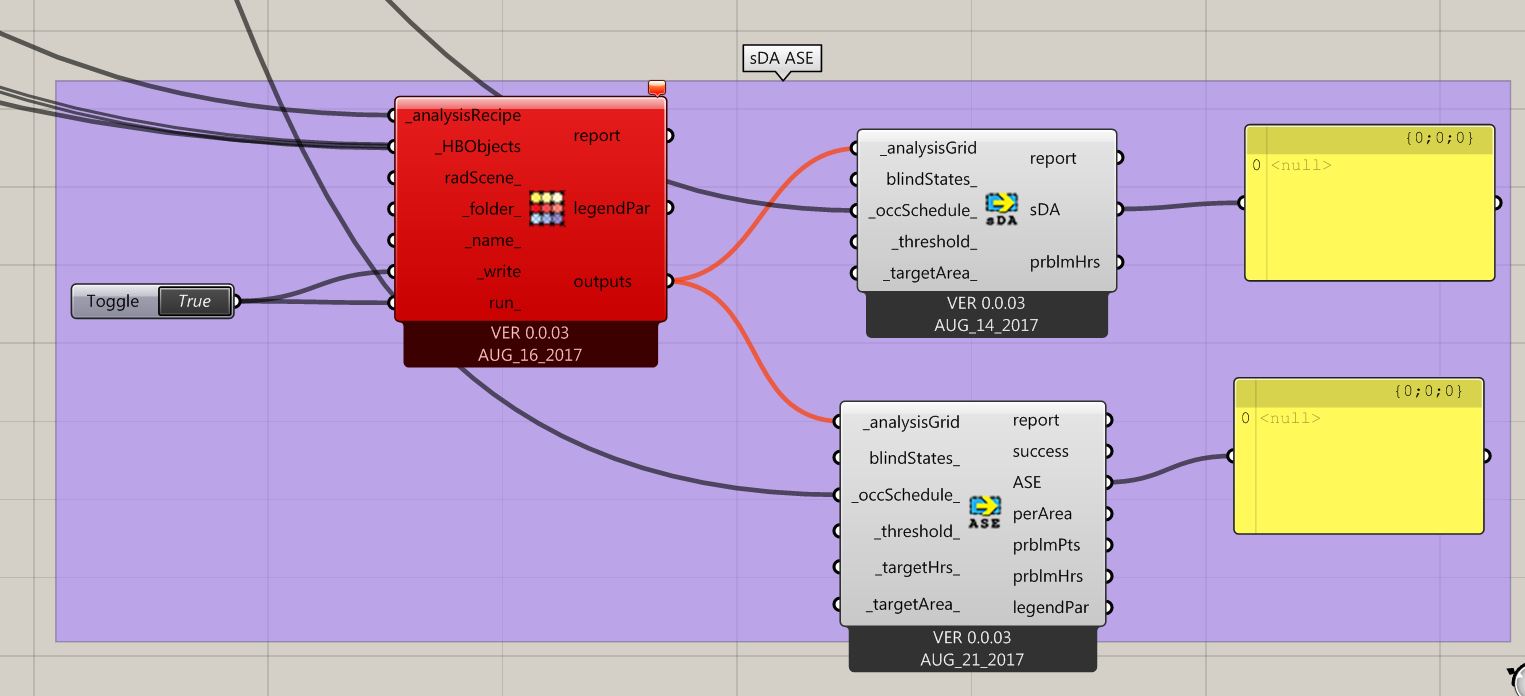
I am trying to use HoneybeePlus_sDA and HoneybeePlus_ASE component to generate annual sDA and ASE , but i am having trouble generating analysis grid. The components say the analysis Grid should be from run Radiance analysis, however I could not generate the analysis grid from the honeybeeplus_Run radiance analysis component too?
Error says
“1. Solution exception:<Rhino.Geometry.Brep object at 0x00000000000079C7 [Rhino.Geometry.Brep]> is not a valid Honeybee object.”
@anupamarana,
You’ll have to use HonyebeePlus components to develop your workflow if you intend to use ASE and SDA components from Honeybee Plus. Most likely, this error occurs because you’re supplying a Honeybee object generated from Honeybee legacy version.
Unfortunately a lot of people cheat with their LEED daylight points unknowingly that the sDA they document is actually just a DA.
In the sDA, every hour where more than 2% of the simulation points (per zone) receive >1000 lux from direct sun, that zone should be simulated as if the blinds were down. This causes rooms close to the facade to trigger blinds that will affect zones deeper into the building volume.
It’s described in LM-83, which the official LEED documentation is also referring to.
It can be discussed whether the LM 83 study was tested on enough cases before it became industry standard because of LEED and LEED has also been criticized for it.
Remember that normal daysim calculated ASE may cause too many points to receive “direct” sun as that is calculated by a few sky patches instead of the real sun position. The HB (and also DIVA) ASE calculations use real sun position. Read more here:
In recent LEED documentation it was also opened a possibility to have ASE above 20% instead of 10% if shade control is well implemented (still doesn’t change blinds schedule and the sDA):
indeed I need to purchase the IES document as soon as possible.
In my understanding DA and sDA differs because in the DA you need just to set an illuminance threshold, while in the sDA you need the illuminance and also the percentage of hours thresholds.
Just to be clear, the difference you are saying here is that the DA is a calculation as the ASE, that you do without shadings, while in the sDA, as per LEED, you need to include shadings. Is this that most people do and they are wrong?
Similarities and difference on LEED sDA and a regular DA
are simulations for every working hour of the year, and in the end, each point will get a percentage of the working hours that it is well lit (usually x % of the office hours are above 300 lux). When every point in a simulation grid is calculated you can check how many of them are well lit in more than half of the office ours. This will show an area of your floor that is described as well lit. This is same method in DA and sDA.
So both matrices usually count how much of the floor has 300 lux in more than half of the working hours. So far, so good:
spatial Daylight Autonomy (sDA), or as in LEED sDA(300lux,50% of time)
and
Daylight Autonomy (DA), also usually 300lux for 50% of the time.
spatial Daylight Autonomy
However, the sDA is much more complex than that. The LM 83 states that for each room, one has to run the ASE and check every hour if there is more than 2% of the floor that receives direct light (0 bounces) in more than 2% of the simulation points.
After that, two other simulations are done as DA with x bounces (i usually do 3 to 7 depending on complexity and time). One of them is run without any glare curtains and the other is done with glare curtains*.
Then the ASE creates a schedule, hour for hour, to describe for each hour if the sDA should look at the DA_blinds or the DA_noblinds.
In the end the sDA is a combination of the DA_blinds and the DA_noblinds, controlled by the ASE. The resulting sDA(300,50%) is always than a DA(300,50%)!
*blinds: There are standard roller blinds configurations, but one can also use trans materials. If an external automatic shading is used, one can also input the schedule for this.
This is highly theoretical, and there exists many public or private workflows to this!
Suggestions on workflows:
Do it as described above with HB and daysim for 2x DA and use ASE to control. This is following how the LM 83 describes it. For 15000 points this is heavy and may lag your grasshopper to death unless you can code the statistics in another software such as Python with NumPy/Dask/Pandas (we have integrated it through Mahmoud’s GH_CPython).
I recommend this method for smaller analysis, but it can become super heavy!
Do glare analysis for each orientation. If this shows that blinds are down 2 hours per day, then do a normal DA,300 and subtract 2 hours daily (or -20 percentagepoint from each point). This “should” fulfill LEED if you argument for it, but it is not directly described in the LM 83.
Use DIVA 4 in Rhino. This is probably the easiest setup for now! However you can’t control shadings (as far as I know…) And also only runs on 1 core of your computer (you can manually split up your file though and combine result files through grasshopper).
Use DIVA 4 in grasshopper and apply the built in “manual” shading and set up how many points close to a window should control the blinds schedule for that window. Also works with “automatic” shading if you have a building controlled automatic shading system. Here you can also dig down into the shading schedules easily. But simulations can get really heavy when they pair windows with simulation grids, so use with caution!
As Method 1, just with a rcontrib 3-phase or 5-phase method to speed up simulation with and without blinds. I haven’t looked into this yet, but I think it will be the perfect tool for open office buildings simulations for LEED sDA. This process can get really fast if you get a decent GPU and use accelerad, see https://www.youtube.com/watch?v=aUvymZXTPGo
Hope this cleared up a little, and probably also confused a lot.
In the sDA output, it is already set as default sDA(300lux, 50% of time). I see where you are able to change the lux threshold, but is there a place where I can change the % of time? Thanks!
I’m very interested in using Cpython, pandas, numpy and dask to calculate annual metrics on heavy cases more efficiently. I wonder if it is ok for you to share the way you did so with Mahmoud’s GH_CPython?
I don’t have access to that script right now, but I have a CPython/Numpy/Pandas examples in grasshopper for peak radiation here:
you may be able to to change it to do your annual statistics. (Numpy is quite easy to select all rows above a certain value (lets say 300 lux) and do a count on that. it runs really fast.)
If your simulation is not taking account for blinds in hours when more than 2% of the simulation points receive more than 1000lux (in an additional “-ad 0” simulation), then that’s exactly what I mean!
It’s all well described in the LM-83 document that the LEED guide refers to. It can be bought for $5 I think.
Hey! Thanks for your explanation, but I am a bit confused with sDA calculation. Can you explain what we should do step by step? Actually I don’t know how exactly I should define the blinds and how the result of sDA with and without blind should be combined