Hi @MichaelDonn
I think your idea here has a lot of merit and is definitely something we’ve been thinking about as well. In our sector (Certified “Passive House” buildings) we have to provide our energy models to a 3rd party reviewer and they require justification and documentation for each data point input in the model (yes… its as crazy as it sounds ![]() ) which is a huge effort and very, very prone to error - although it (3rd party review) yields tremendous value to the teams as well. You’d be amazed at how many errors are made in energy models, even by really experienced practitioners…
) which is a huge effort and very, very prone to error - although it (3rd party review) yields tremendous value to the teams as well. You’d be amazed at how many errors are made in energy models, even by really experienced practitioners…
Regardless: for the past year or so we’ve changed our modeling strategy to one where we use ‘outside Rhino’ databases to manage all the model input values, which can then also store the ‘source’ information in the same record. We specifically use a cloud database called AirTable, but the general idea could work with any database I’d think. Basically: we store all the actual values of course, but then also any associated links and PDFs and whatever else in the same record, then we have tooling which pulls those DB records down into Grasshopper and uses them to build up the Honeybee Model elements automatically when the GH-solver is run.
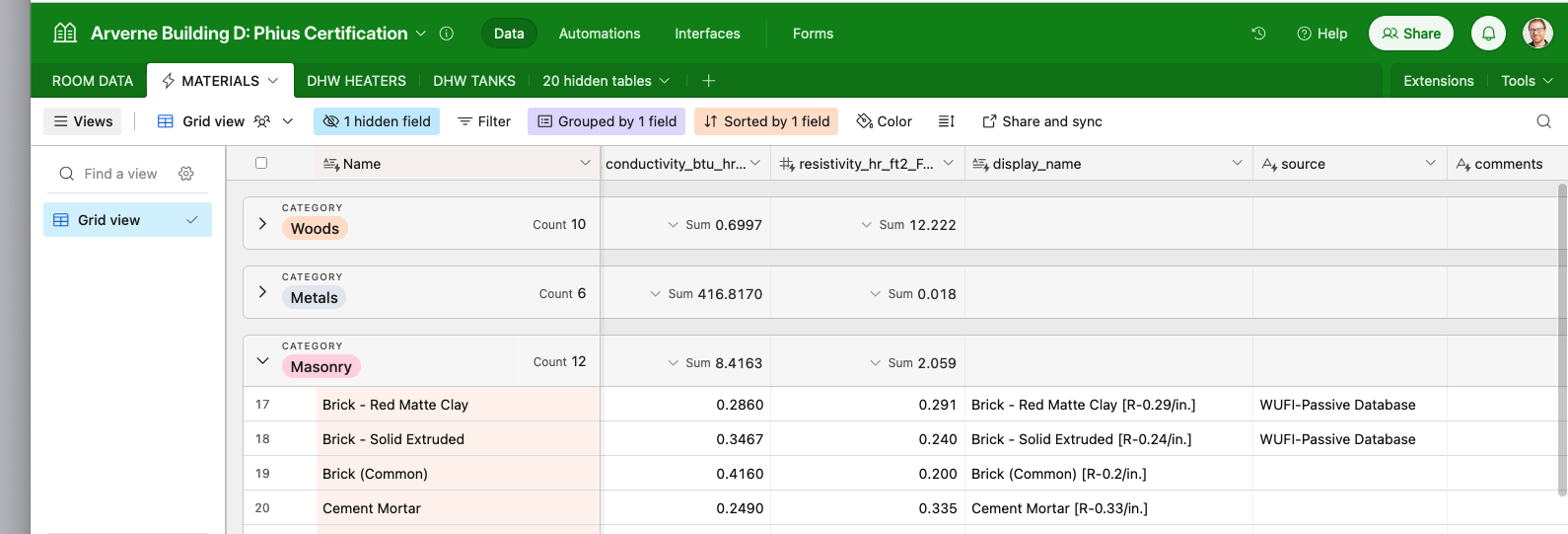
For sure this is useful for Materials, as you suggest, but the same logic holds for windows, constructions, loads (room-vent-flow-rates, etc…), heat-pumps, thermal-bridges (psi-values), fans, pumps, piping, ducting, … each of those has relevant ‘source’ information which is critical to have for effective 3rd party review and approval.
While the above approach works, it is still prone to losing track of the data since the ‘source’ is still not embedded in the actual data itself, but only there via linking / referencing to the database record via some sort of ‘key’ (usually the name, not ideal…). We basically have to hand over the DB along with the HBJSON for the reviewers to be able to make any sense of if.
To my mind, a better approach would be to enable the inclusion of this type of ‘meta-data’ in the data item itself, as you suggest. We’ve been thinking about how to implement something like this so that we can embed this ‘meta-data’, and turn over a single HBJSON file to our 3rd Party reviewers. We think this would dramatically improve speed and accuracy of the model review.
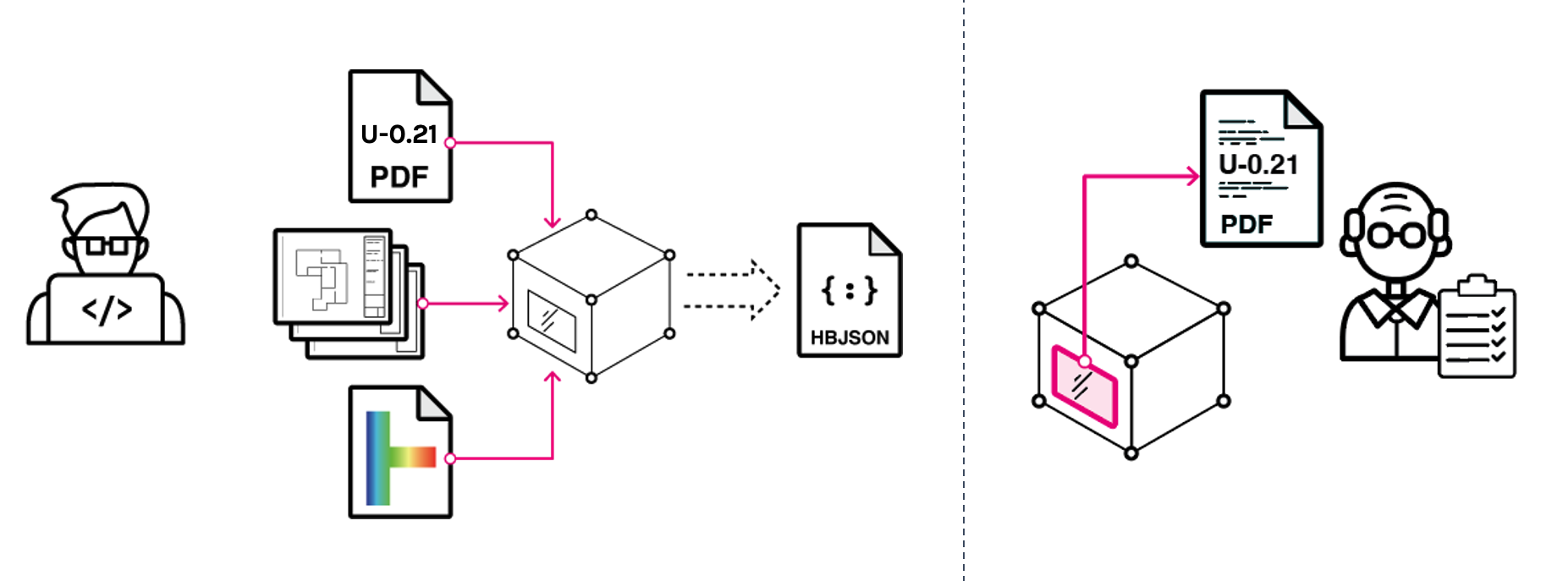
By using a cloud-database, I’d think this data could be in the form of a record url, rather than the actual PDF itself, which would keep the HBJSON files manageable.
In addition to the ‘source’ meta-data, we are also trying to figure out a method of embedding the ‘unit’ information in the data point as well. This is partly because we working in both the US and EU and so are constantly bouncing back and forth between unit systems.
We’ve tried to come up with a few different methods for managing this unit data, including the ‘hb-units’ package which includes a ‘Unit’ type with exactly this kind of meta-data alongside the actual numeric value. We use this for almost all of our own libraries since it really helps to clarify things for us and avoid all sorts of errors.
I the short term, I’d suggest using something like the EnergyMaterial’s user_data to store any such references or ‘meta-data’ information. That is a simple key:value storage which should travel along with the object throughout its life-cycle. You could embed this information at the Material’s creation time, and then pull it out again at the end in order to execute your validation routine. Maybe in the long term a more official ‘meta-data’ plugin or extension could be developed to help manage these types of challenges.
all the best,
@edpmay