Hi all,
I have been experimenting with a new workflow for managing materials and assemblies lately, and thought I would share here in case it was helpful for anyone else who has trouble managing all that data in an easy way. This workflow uses AirTable, which is an online database tool, in order to collect and manage the data, then a simple Grasshopper script to download the data and build the HB-Constructions.
Challenge:
While I love building the models in Grasshopper, I don’t like managing my material and construction data in Grasshopper. I find the definitions quickly get very large and unwieldy, and I find I am repeating myself often when working this way. I’ve tried many techniques, but I just don’t like it. Grasshopper is great at lots of things, but storing and managing data of this sort doesn’t seem to be one of them.
| Yuck…

I kept finding it was also hard to share data between GH definitions, and it was easy for things to get ‘out of sync’ when working on many models at a time.
(Note: this same issue can be generalize to pretty much all model inputs, but for now just taking the case of the materials and assemblies as illustrative of the workflow…)
Solution 1: Use the Honeybee Libraries:
Honeybee of course has some great tools for managing material data outside Grasshopper. Materials and Constructions can be stored as HBJSON objects and re-built at runtime by Grasshopper. This is great. But it means keeping data in json files, which I found to be a challenge to visualize, maintain, and edit.
Solution 1b: Use CSV Files / HBJSON Files:
For a time, I was using these local HBJSON source files alongside an assortment of CSV files to manage project input data. Using this workflow, all the various the data was organized in simple files and then used to build the materials and constructions at runtime within Grasshopper.
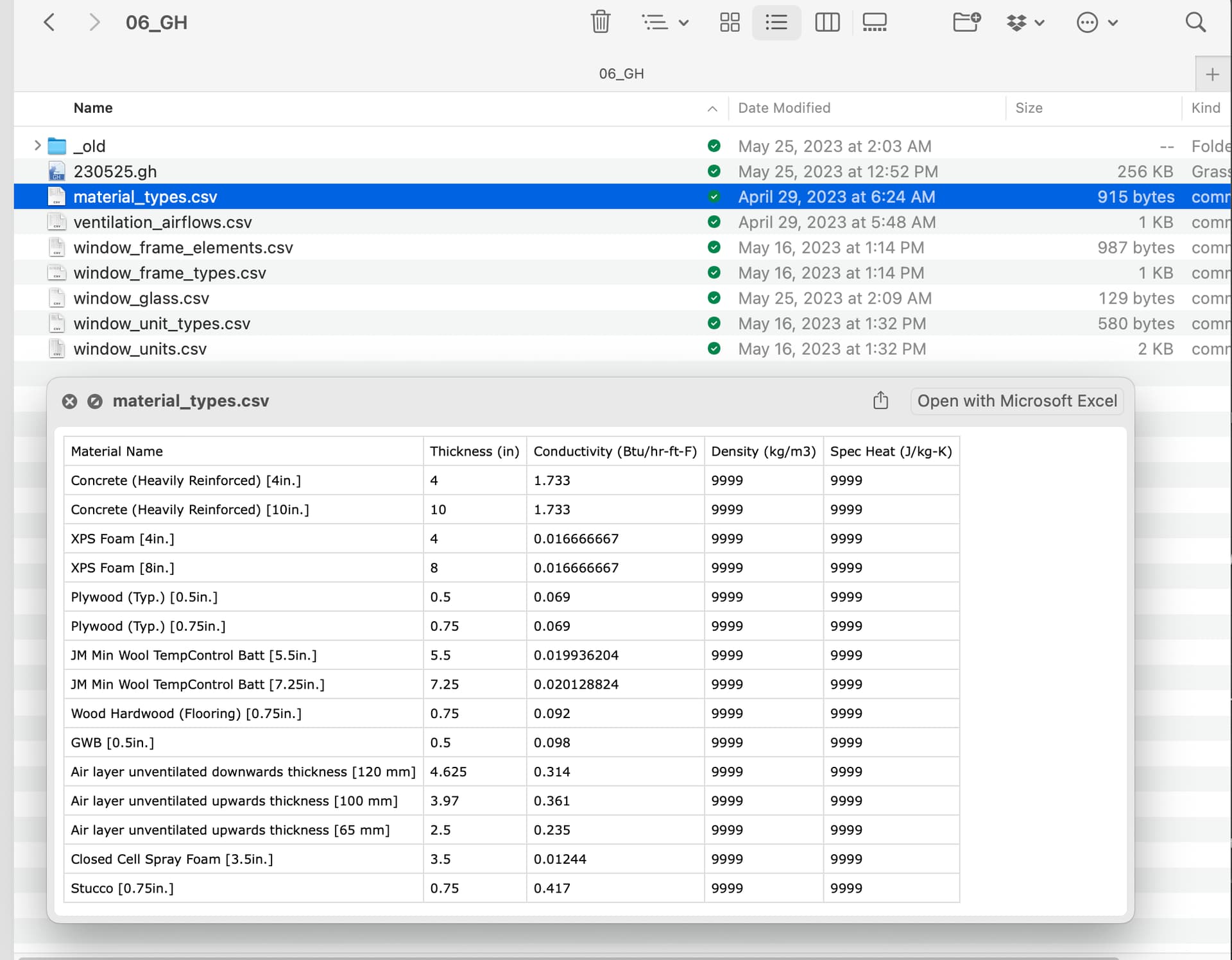
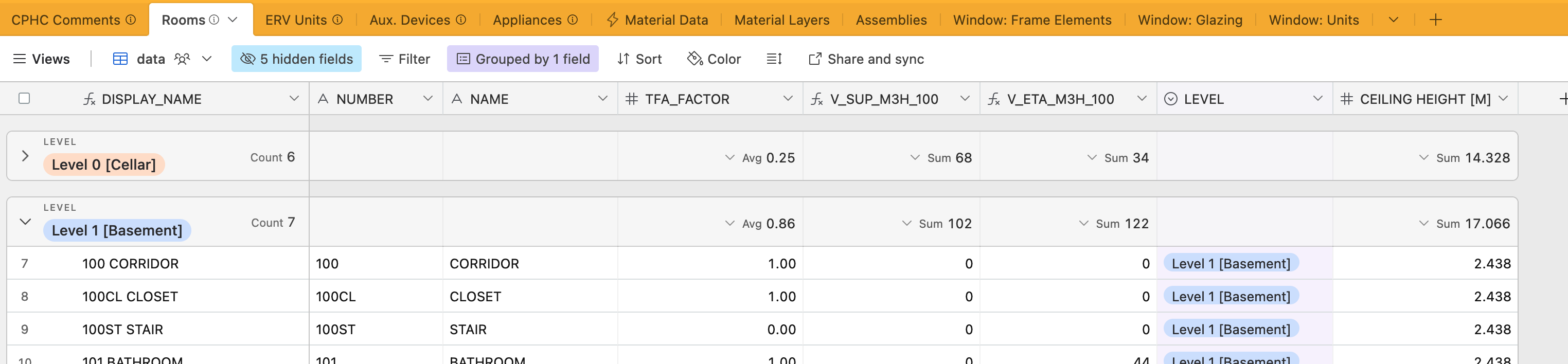
This definitely worked well to reduce the complexity of the Grasshopper scenes. This also allowed us to more easily navigate the data and update the attributes in a simple tabular format. We started moving all relevant project data out to these files such as room-data (names, numbers, ventilation flow-rates, etc..) windows, ventilators and mech. equipment, appliances, and of course materials and constructions.
However we still found it challenging to share data across projects easily, and it was still easy to make a lot of errors. Since the files we all saved locally, it was still easy for them get ‘out of sync’ when sharing and collaborating. But more generally, having all the data in these types of files seemed to limit our ‘visibility’ into the data (not sure if that is right word, but something like that).
Solution 2: Use AirTable:
This is the solution we are experimenting with now to see if we like it better than the CSV/HBJSON file method. Its an experiment, so we’ll see after a few projects if it seems better or not. For those not familiar: AirTable is a simple online database tool with some nice UI features. They have a great free-tier which is what we are using for all these projects so far.
| Shared Construction Materials Database
Using this online database, it is easy to create a centralized material library which is consistent across all our projects, since it (the material database) can be stored separately and then easily referenced (‘synced’ I think they call it) into any specific project’s AirTable database.
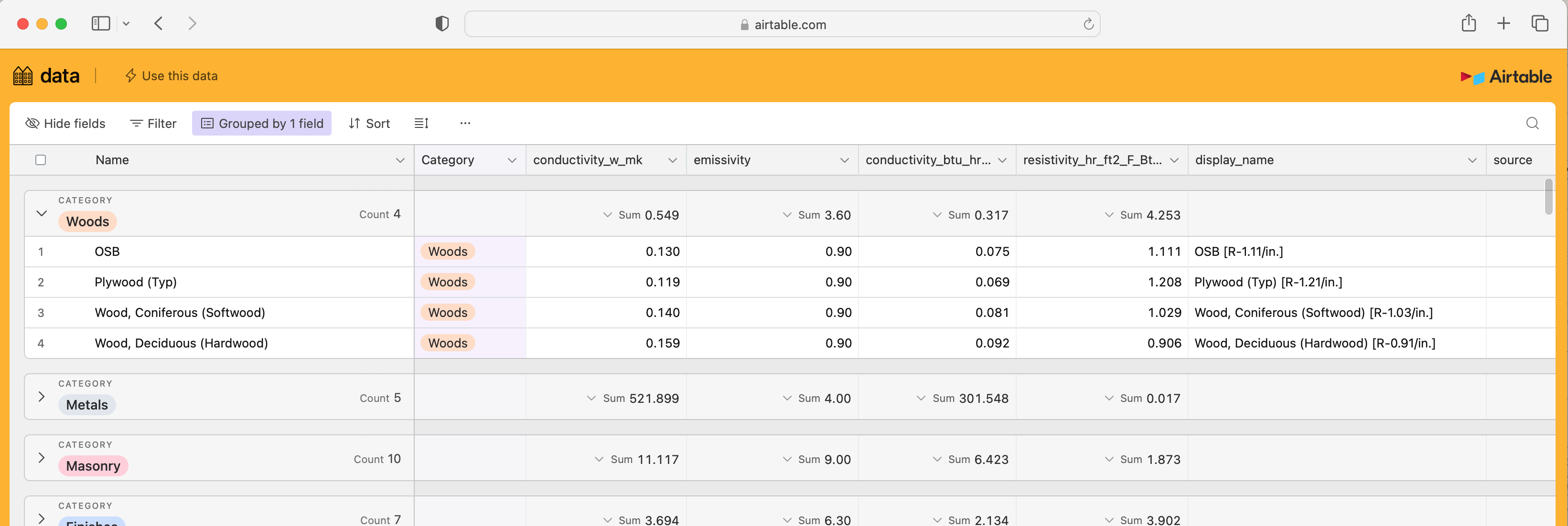
| Construction Layers
Once the shared materials are referenced into a specific project database, they are then composed into actual Construction Layers unique to the specific project in question (since the HB-Constructions require a specific thickness, which the generic materials do not have).
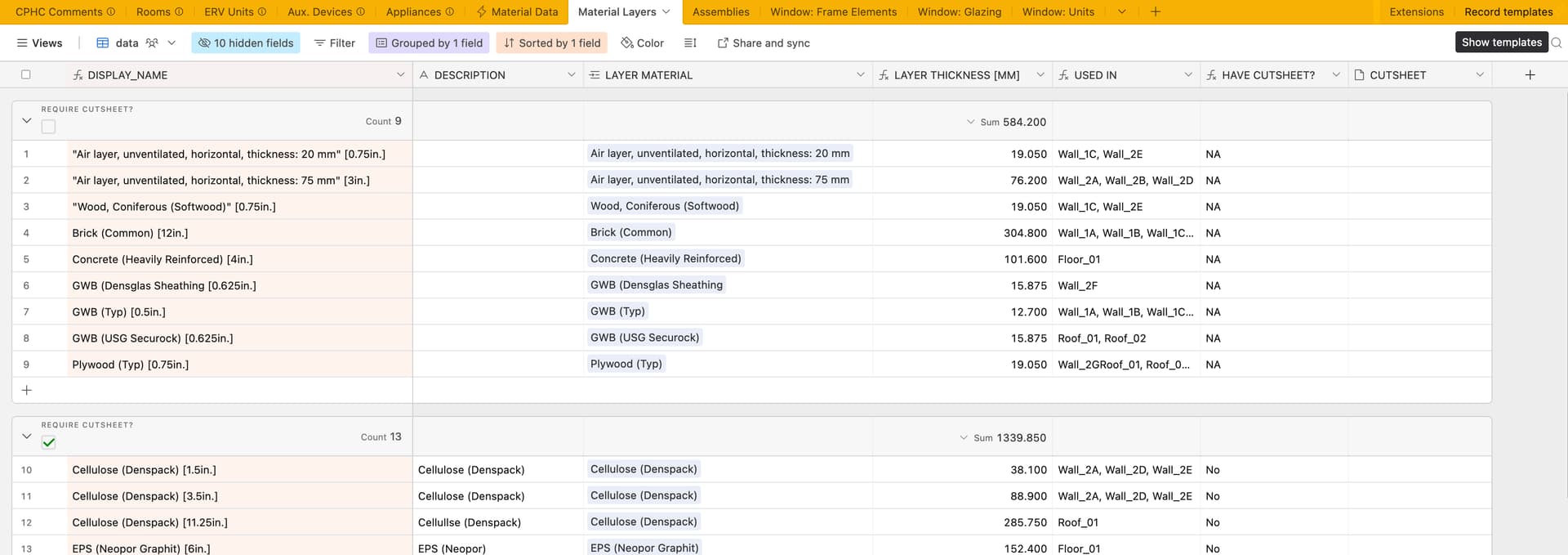
We can also add useful fields to these assemblies here for things like verification (ie: do we gave a cut-sheet with the source data?) and conversions (IP ↔ SI)
| Construction Assemblies
Once we have all the Construction Layers built, we can easily combine them into actual Constructions made of one or more layer in another view within the project’s AirTable database:

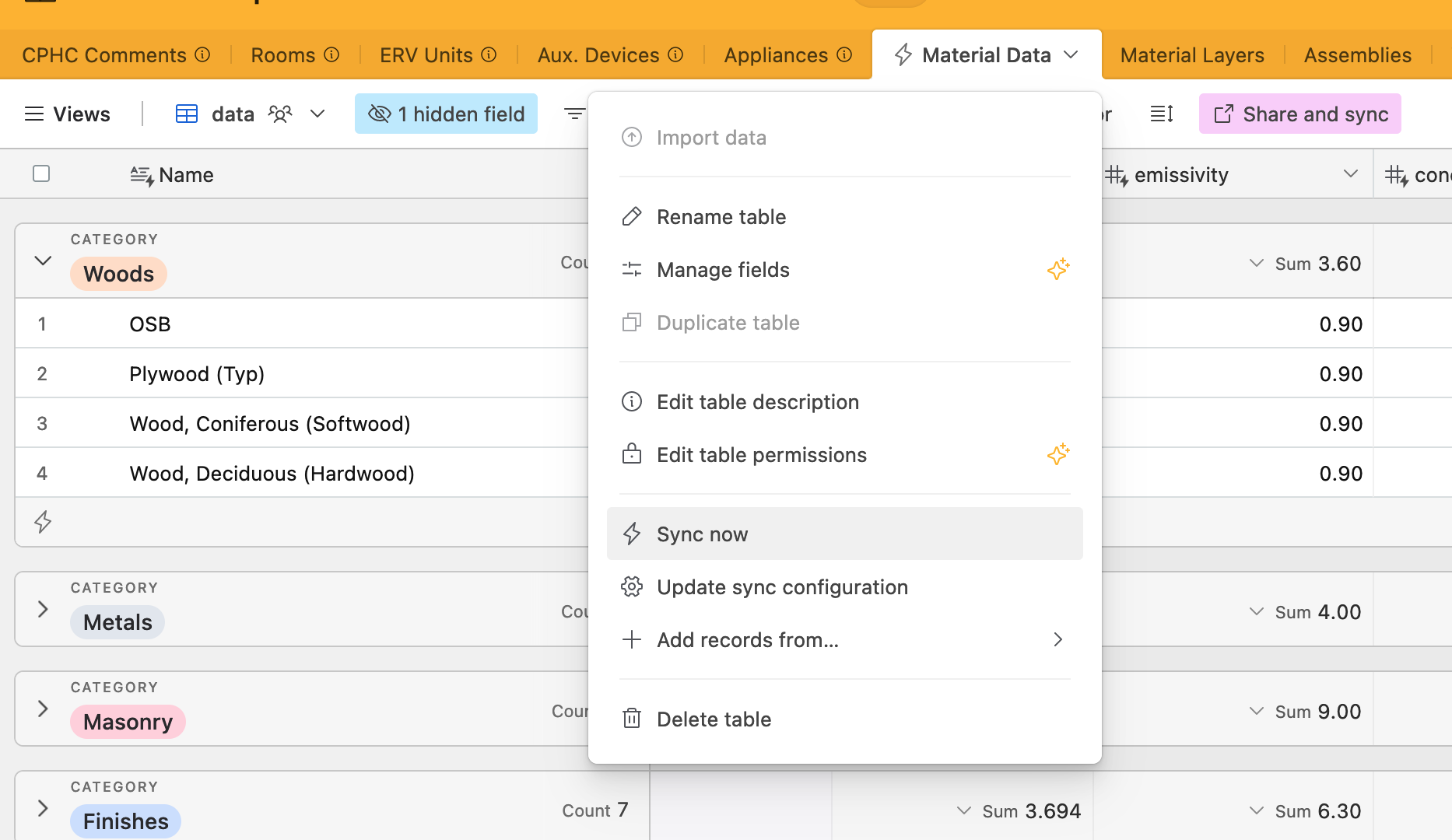
And because this is a relational database, and not just a series of CSV files, when things like name-changes or other attribute edits occur to any of the elements (materials, layers, constructions), those changes propagate backwards and forwards throughout the entire system.
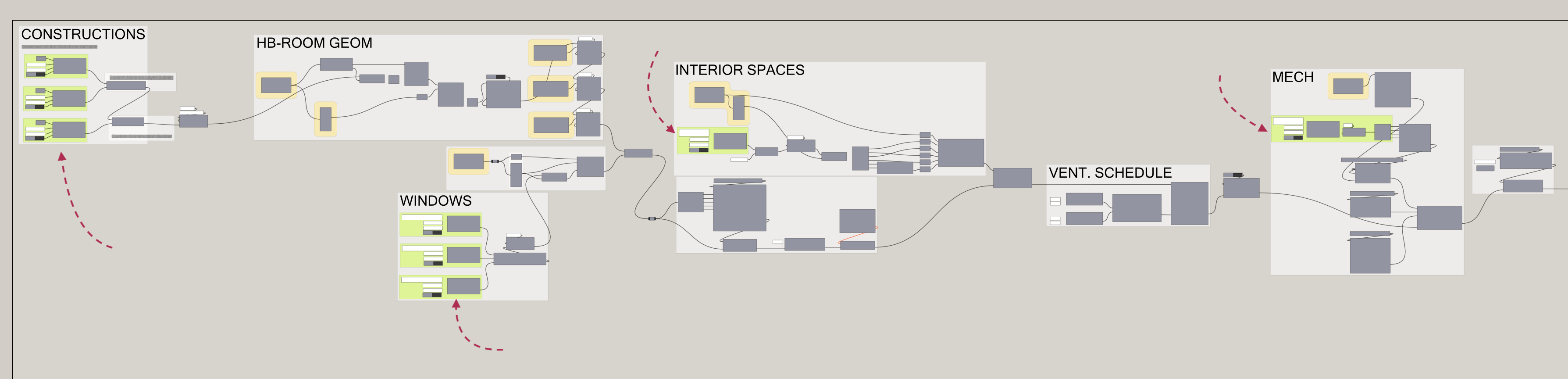
| AirTable GET
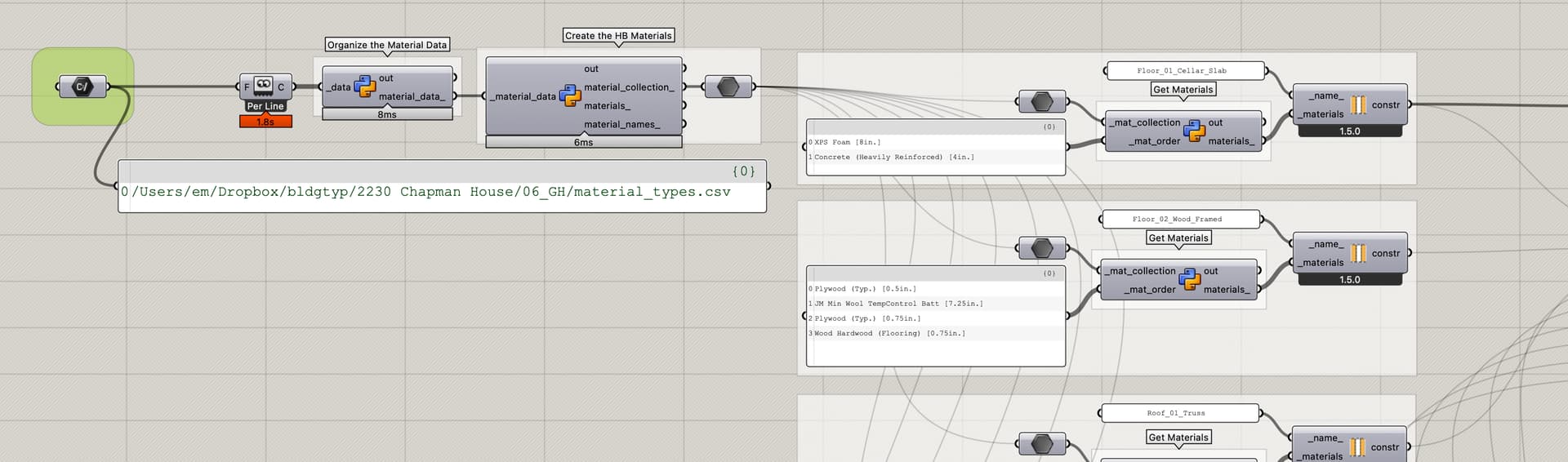
Now that we have all the input data organized, the next step is to download all of the data from these tables into our Grasshopper file in order to be able to use it within our project definition. There is a GH package available (I believe Mallard?) but since we’re just downloading a little bit of data, it is very easy to write a simple GET component using ladybug_rhino.download as our starting point. We can just adapt that code a little to our purposes here to get all the data from AirTable, and maybe add a few data-classes to cleanup and structure the incoming data.
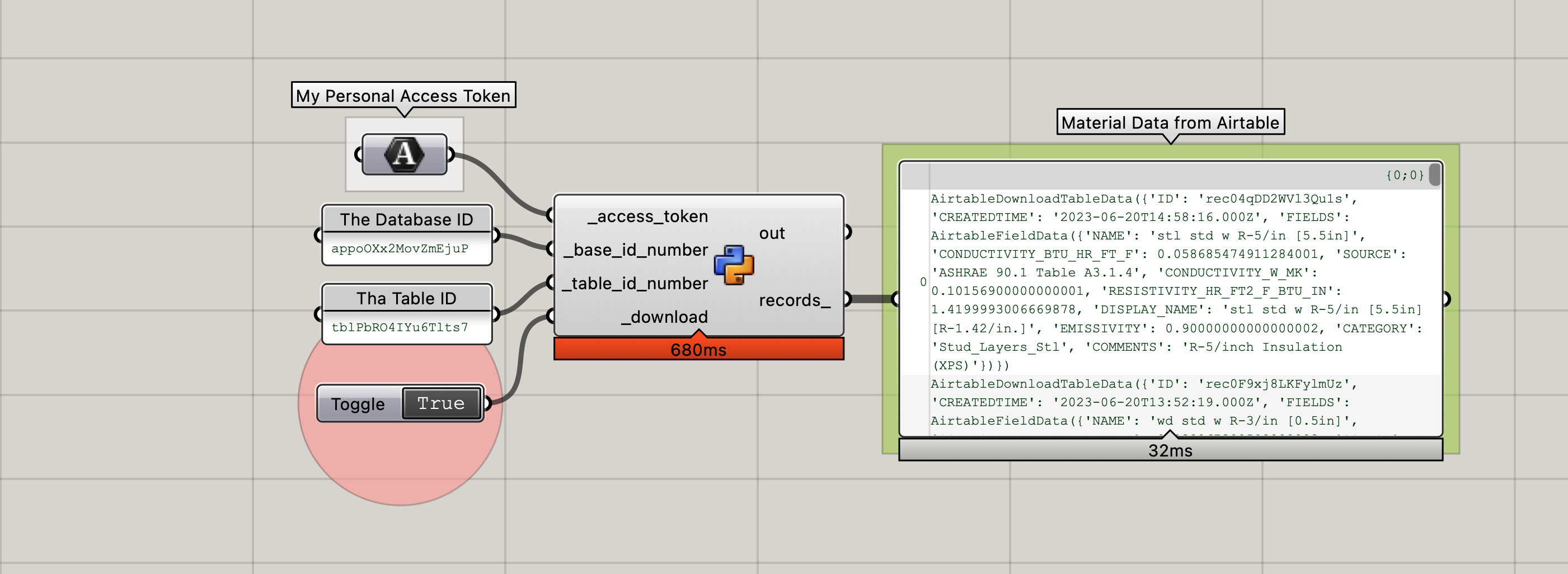
| Download Data, Build the HB-Energy Constructions
In the example case here we would need to have three separate GETs: Materials, Layers, and Constructions. Once we have all the data in GH, we can combine it together to create our HB-Materials and HB-Constructions for the specific project within our Grasshopper definition. For our own specific case and project table format, we have created some simple convenience components which do this object creation step, but you could also just use native Honeybee-Energy components as well of course.
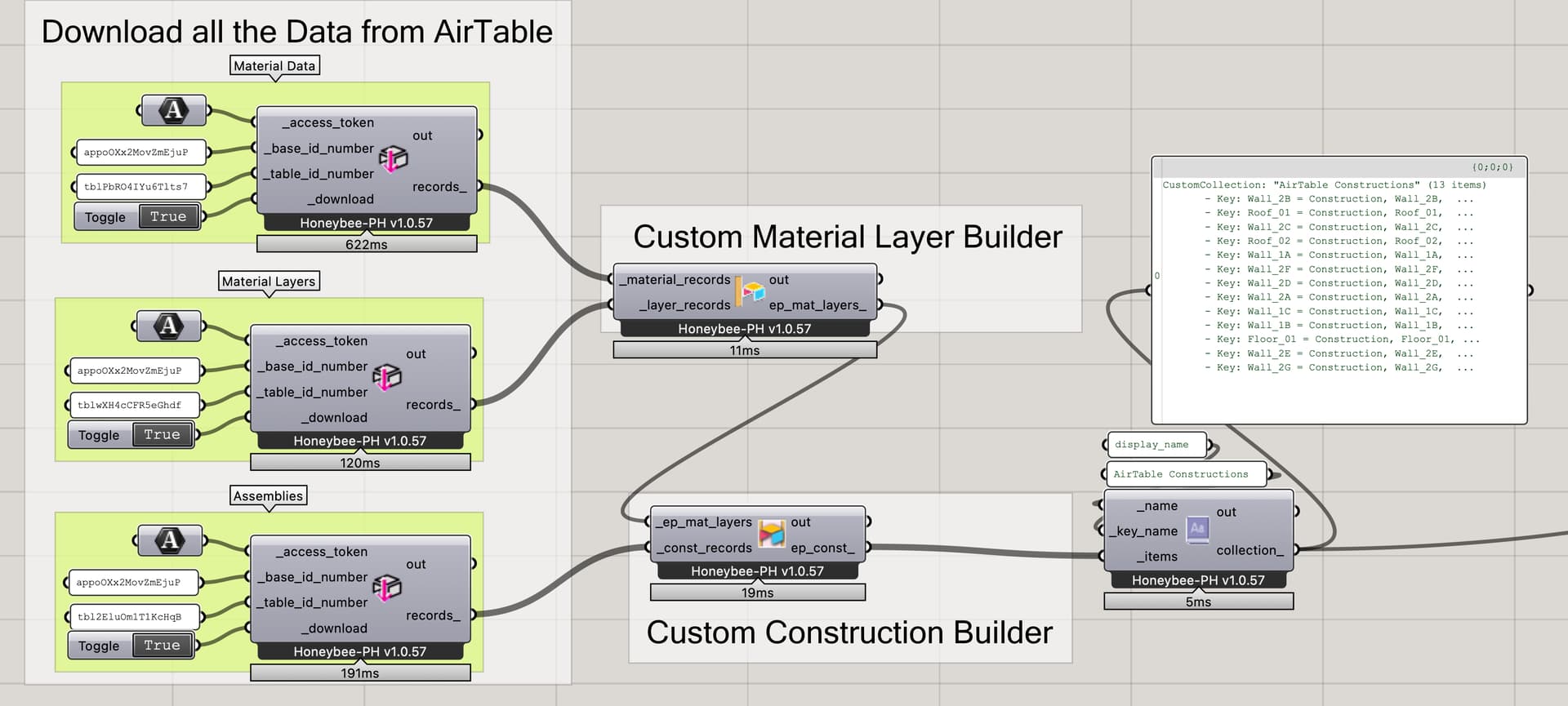
Now that we have all the constructions in Grasshopper, we can use any of the normal techniques and tools for applying them to the model surfaces as required.
Once we have the basic building blocks and components in place we can use this technique anyplace we have repetitive and/or shared data we want to use as inputs. We are using this method for constructions, but also for windows, room-data, and mechanical equipment amongst others. We are building one database for each project, and storing all the relevant project specific data there, alongside the linked in material library from the centralized / shared database.
Some AirTable things to consider:
-
The API for AirTable is pretty easy. Keep in mind the records are limited to 100 per request, so you need to chain together requests using their ‘offset’ param to get all your records if you have more than 100 in a database. Check out their API documentation or the example attached for how we did it in this case.
-
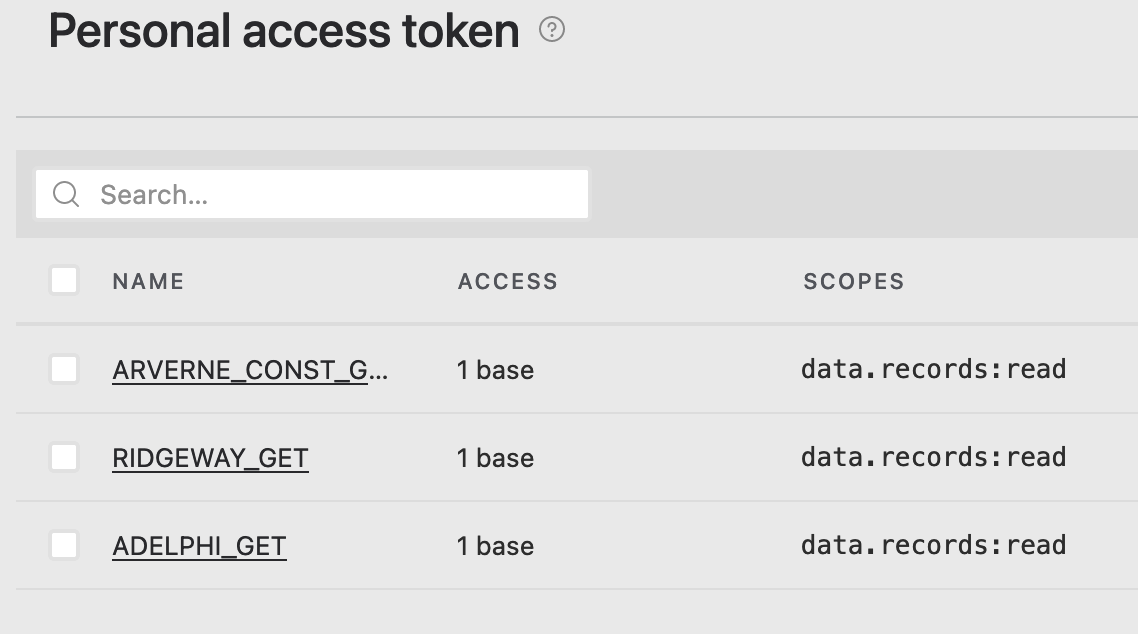
You need to setup a Personal Access Token on your AirTable database before any downloading will work. These are configured on a per-project basis (I think?). Check out the AirTable documentation for more on those. For our case, since we are just downloading, I set the scope of my tokens to
data.records:read
if you want to push data back to the database from GH you would probably meed to set that up differently. But if you are just reading, this works well. -
I haven’t hit them yet, but I think the AirTable free tier has some pretty low limits on total database size (1200 records per project database?) which might make this technique impossible for really large projects.
So: just sharing this in case it seems helpful for anyone. So far it seems to be working well, but I’d be curious if anyone else has found even better methods for storing, managing, and linking this sort of data into GH models?
example file attached with the download script in case anyone is interested.
all the best,
@edpmay
airtable_example.gh (10.2 KB)