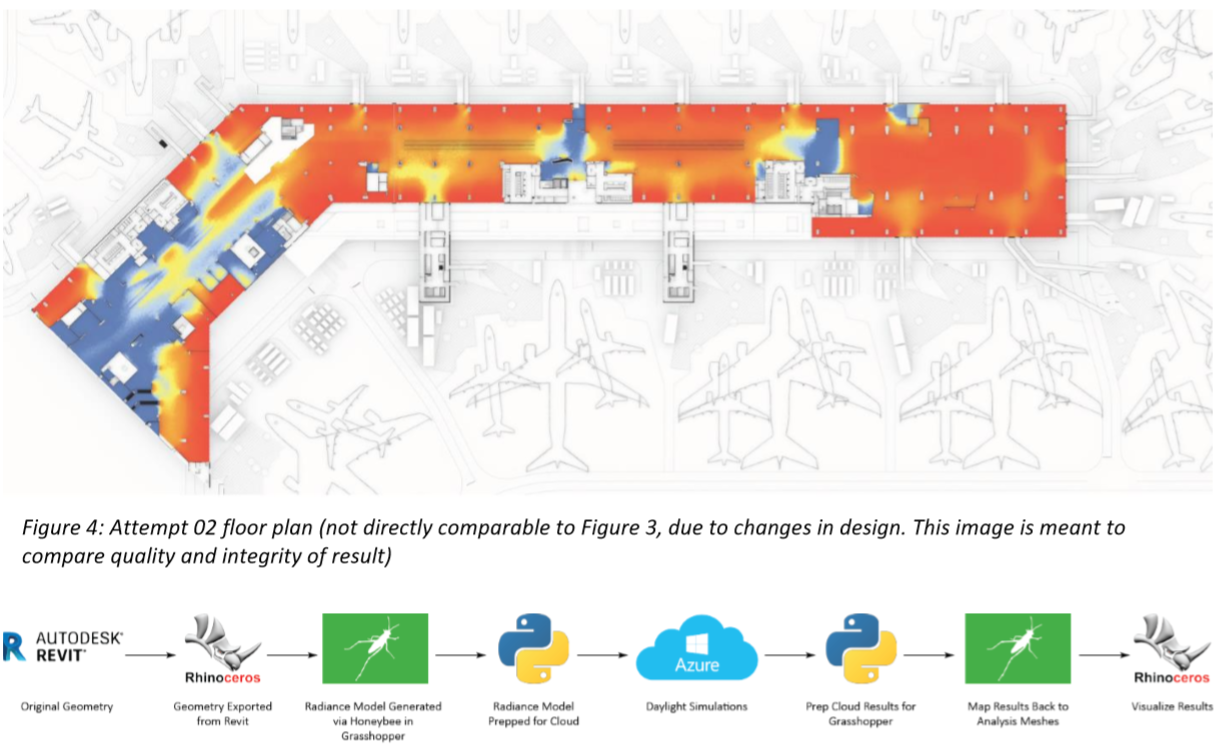
Late last year, Mili Kyropoulou, Paul Ferrer and I worked on a daylighting study for the proposed extension for San Francisco International airport. With about 300,000 sq ft of floor area, and over 109000 illuminance grid points, the model employed for this study far exceeded the capacity of any conventional daylighting tool or a conventional desktop computer. For example, the matrix operations pertaining to the calculation of Annual Sunlight Exposure required a system RAM of nearly 200GB and involved single files exceeding over 20GB of hard-disk space.
We used a pre-release version of the library now known as Honeybee[+] on local and cloud-based machines for nearly the entirety of our project. A high-level technical overview of this study is documented in a paper presented by Mili at the PLEA Conference in Hong Kong last week (link, direct-download).
Mili and Paul work on the design and research of high performance buildings at HKS Line.
A precursor to current and future functionality: Thanks to the continued efforts of @mostapha, and more recently @AntoineDao, some of the challenges that we faced during our project have been addressed through improvements and enhancements in the source code of Honeybee[+] and the Ladybug Tools API. These include the use of database tools for better management of extremely large data-sets, better cross-platform integration through run-managers and bash support, the on-going development of a dedicated cloud service and the availability of ladybug tools libraries on PyPI. While there are still some hurdles to be cleared for the seamless integration of locally-prepped and remotely-run simulations, I expect that in the near future, projects of this scale will be considered business-as-usual than be discussed as case studies.
(Mostapha had discussed certain aspects of this project last year during his talk at Philadelphia Dynamo Users Group: https://youtu.be/RB9ly1sRxtc?t=4562)
Really cool stuff @sarith, Mili Kyropoulou and Paul Ferrer! I’m not sure how much you’re allowed to reveal here but I’m being nosy about the nitty gritty/back end side of this study which isn’t really discussed in the paper:
Did you guys use Docker containers to model this or plain VMs on Azure?
Did you make use of Azure Batch or some other service to distribute your workload for you or did you write your own custom logic to run this simulation?
Did you do all your post-processing (sDA from raw results and the like) on Azure or did you download the results files locally and post-process there?
Any idea what the cost of running this simulation was roughly? Are we talking $10, $50, $100, $500, $1000+?
How approachable would you say this process is for a normal engineering consultancy? Do you reckon they need some specialised teams to do this? Would the infrastructure required to do this be something they would be willing to just pay for like a service?
(cheeky question) On a scale of 1 to windows 98 how bad was it trying to render that mesh in Grasshopper?
Hi Antoine,
No problem sharing at all! The work presented at PLEA has actually progressed quite a bit further in the months since we submitted the paper, so I’ll answer as it pertains to the original paper as well as the current state of development:
For the method detailed in the paper we were using a single Azure VM running Ubuntu and then SSH’ing a series of radiance commands via a local python script. I’ve since written a tool using the Azure Python api to instantiate ‘n’ number of VM’s referencing a predefined custom Ubuntu image (with all the necessary software pre-installed) so we can split up our calculations and run things a bit faster. But to answer the original question: no, Docker was not used.
Azure Batch is really intriguing and we actually just started looking into it. However, for the time being, all the logic is custom written on our end to manage the collection of virtual machines as well as how all the data gets uploaded, subdivided and calculated. We’re currently using the standard multiprocessing library for task management but will be switching to asyncio pretty soon to improve the performance.
All post processing to get the metrics was also done on the Azure machine.
The only parallel benchmarking tests I have that include cost were done for annual DGP calcs instead of a grid-based study, but the cost is very reasonable all things considered. For example, running an annual DGP study with 100 virtual machines took a total of 24 minutes and cost us roughly $1.48. The method demonstrated in the paper was only using one virtual machine for about 14 hours straight. I believe the hardware configuration was set to an ‘H’ series profile which would pencil out to around $30-40 for each run.
That’s a tough one. The LINE studio at HKS has an interest in building out a custom cloud pipeline for use in a variety of other tasks with daylight simulation being just one of them. So in our case it makes sense to spend the time to build it out, but yes in the current state it also requires a fair amount of specialty knowledge just to turn the thing on and start getting results. We’re planning on building out a simplified UI and making it available to our firm but it might be a while before we get to that point. However, in most scenarios I think it makes a lot sense for this type of thing to be a service that gets contracted out.
Right around Windows ME . Grasshopper did not like that mesh one bit, but that rendering was actually done in 3ds Max. We built a plugin to visualize Rhino mesh colors in Max based off a method proposed several years ago on the Grasshopper forums

 [+] FTW!
[+] FTW!