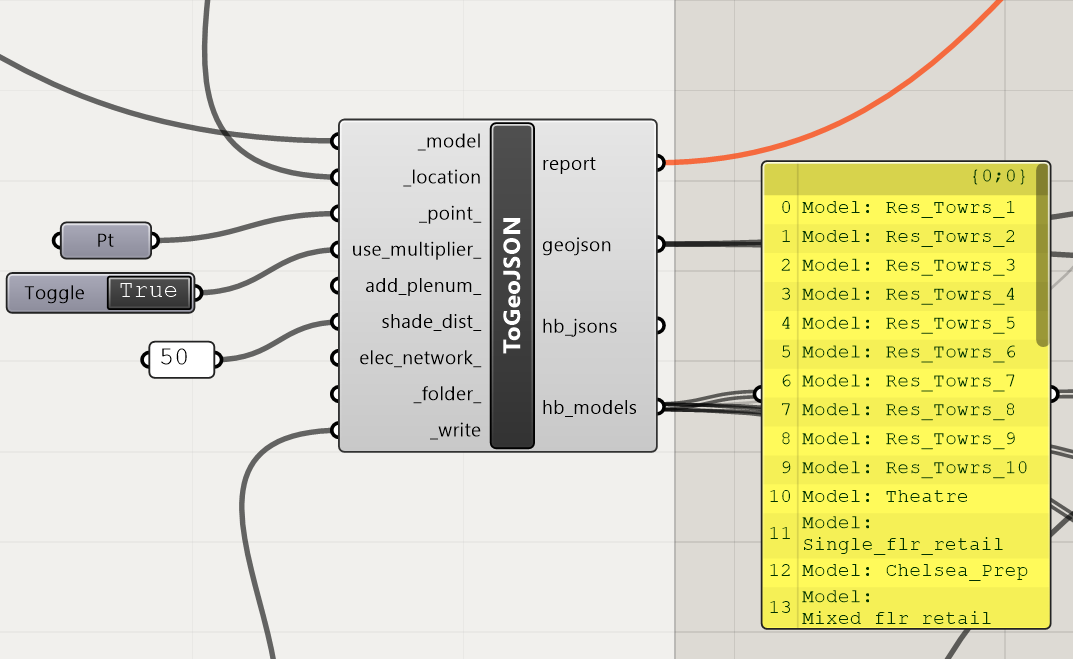
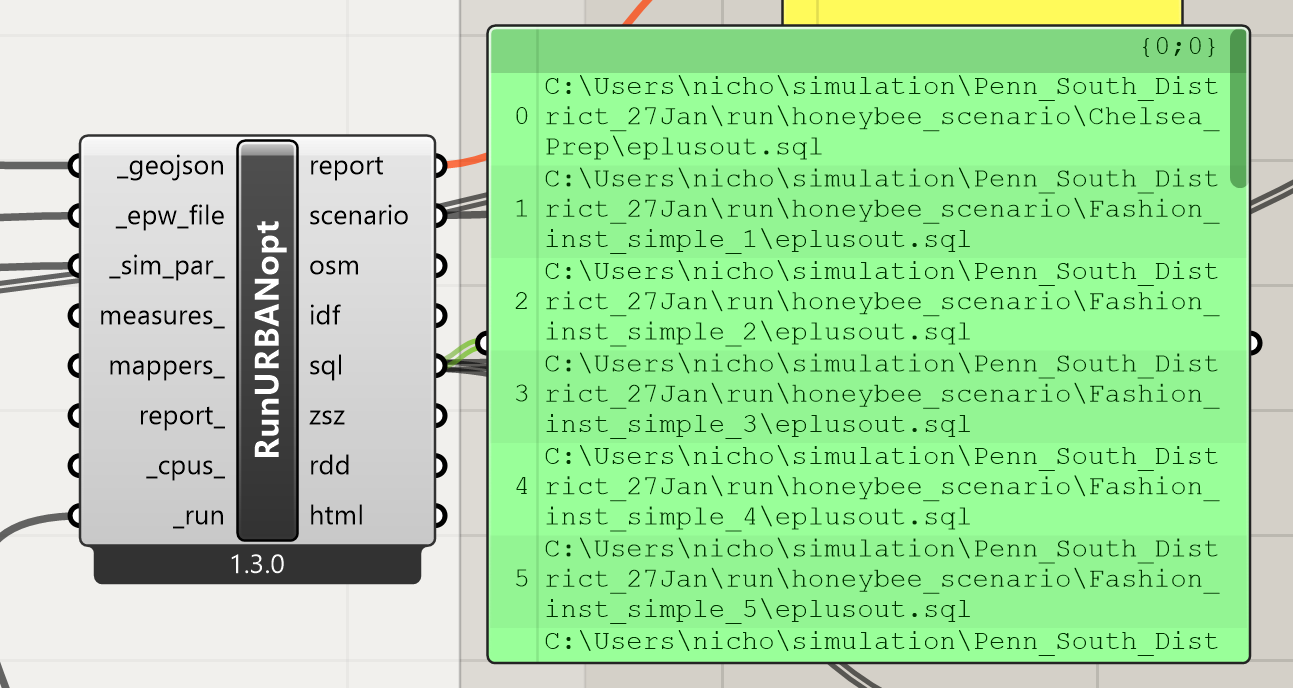
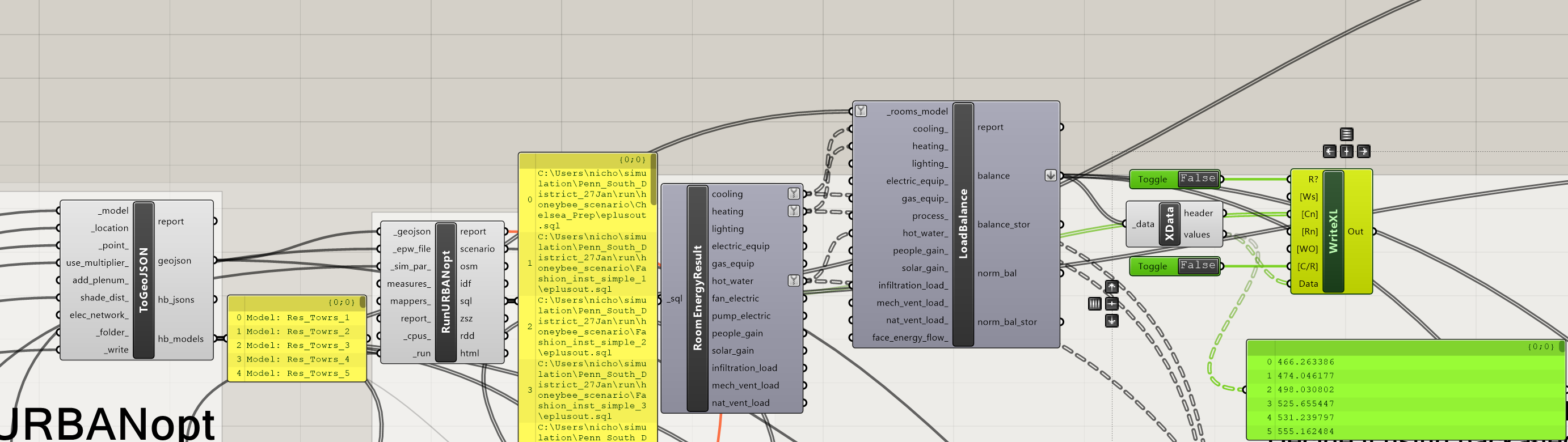
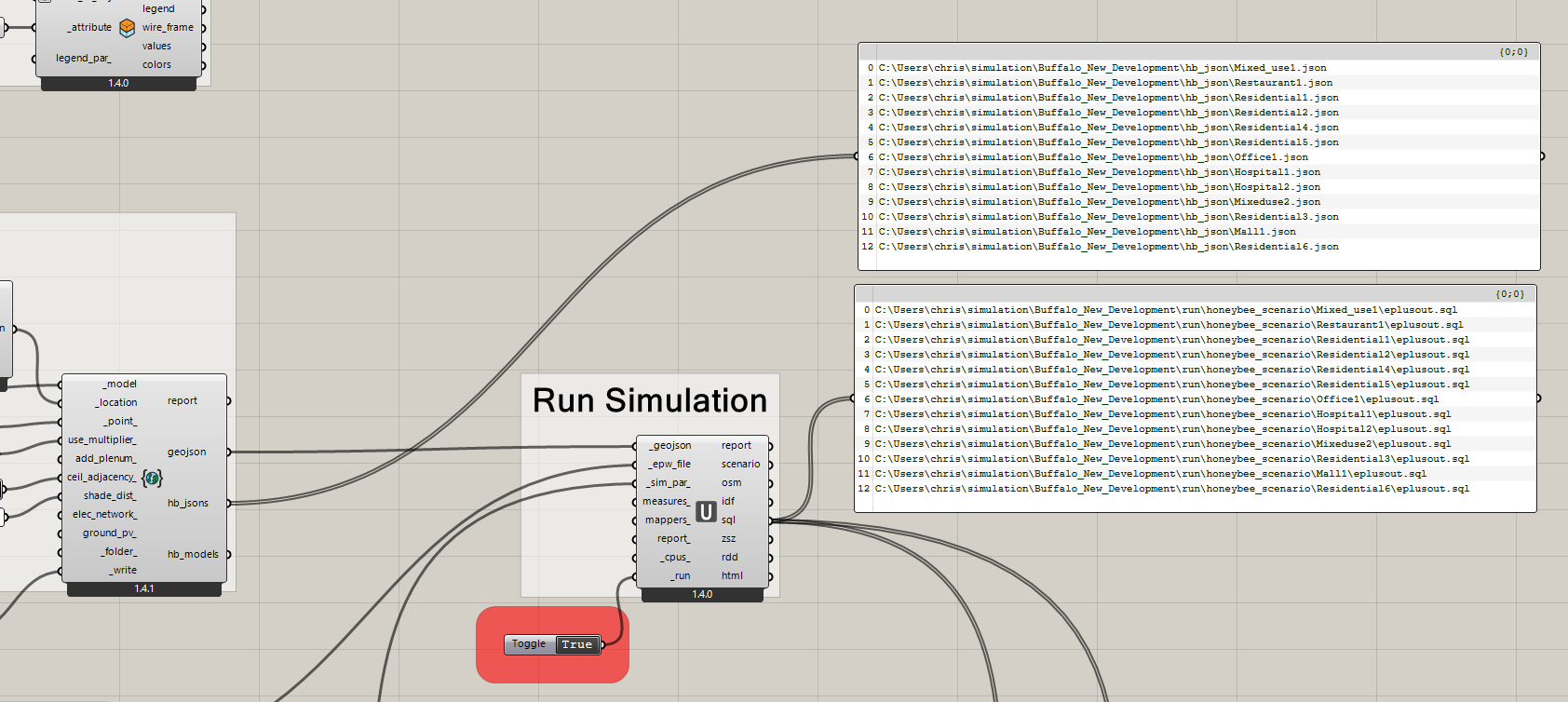
I found that the DF GeoJSON component has one index order for the HB Models. When the data passes through the URBANOpt component, the order again changes.
When I try to Write to Excel and name the columns, I cannot use the HB Models. I am also now very much concerned that the LoadBalance cannot possibly be correct when reading from the URBANOpt - RoomEnergyResult components.
The SQL results from URBANOpt cannot be directly connected to the LoadBalance from RoomEnergyResult because the HB Models are in a different order. They seem to match, because the length of the list matches, but they are not connecting the loads to the correct structures. Is this true? If so, how do I get around this?
I figured out how to do this manually with three buildings today in a different model, which led me to the realization above.
If you are not able to see what takes place. From GeoJSON/HB_models the order is
0 Res_Towrs_1.json
1 Res_Towrs_2.json
3 Res_Towrs_3.json
…
Where the data comes out of URBANOpt in SQL, the order follows
The honeybee_scenario.csv still reads out of URBANOpt as
Res_Towrs_1
Res_Towrs_2
Res_Towrs_3
…
Since the LoadBalance component requires the HB_models input - which is not available from the RunURBANOpt component - the orders of the structures are going in incorrectly. I do not see anything in the component code for LoadBalance that would make me think it is doing anything but comparing the length of the list from HB_models to that of the length in each type (e.g. “cooling,” “heating,” etc.)
def check_input(input_list):
"""Check that an input isn't a zero-length list or None."""
return None if len(input_list) == 0 or input_list[0] is None else input_list
if all_required_inputs(ghenv.Component):
# extract any rooms from input Models
is_model = False
rooms = []
for hb_obj in _rooms_model:
if isinstance(hb_obj, Model):
rooms.extend(hb_obj.rooms)
is_model = True
else:
rooms.append(hb_obj)
# if the input is for individual rooms, check the solar to ensure no groued zones
if not is_model and len(solar_gain_) != 0:
msg = 'Air boundaries with grouped zones detected in solar data but individual ' \
'rooms were input.\nIt is recommended that the full model be input for ' \
'_rooms_model to ensure correct representaiton of solar.'
for coll in solar_gain_:
if 'Solar Enclosure' in coll.header.metadata['Zone']:
print msg
give_warning(ghenv.Component, msg)
Essentially, when the data comes out of the LoadBalance component, it is not possible to know if the load is being connected to the right HB object, and which order is correct by the end of the pipeline. @chris If I am wrong, please let me know. If I am right, please help!
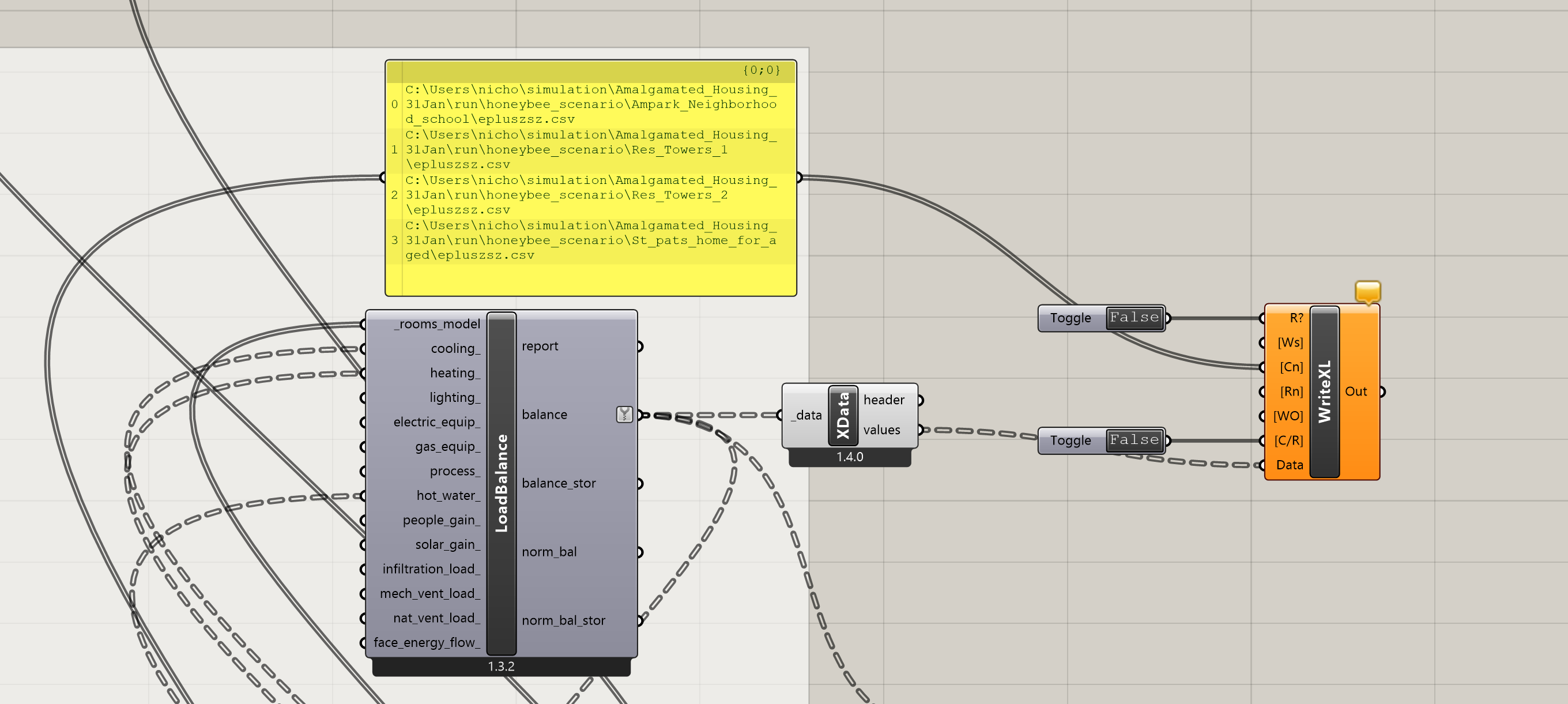
The best, worst approach to solving this is to stick the SQL path data into the Write to Excel component column name. That is the only way I have found to get the order correctly. Unfortunately deconstruct does not work on an SQL path so the entire path will serve as the spreadsheet headers. It is up to you to manually parse the headers or use pandas or something to rename the column headers that are otherwise wrong from the URBANOpt, RoomEnergyResults, LoadBalance, to Write to Excel pipeline. Do not use the HB model names as headers from LoadBalance as column names. They are certainly wrong.
The Load Balance will always be correct as will any Color Room or Color Face visualizations since all of these components have some sophisticated matching routines that run under the hood.
I can see why the order mis-match could be annoying for anything other than these components, though. You can see in this line that we just take the order of the simulation result folders as returned by os.listdir. So this is what currently determines the order of the output files:
We have the GeoJSON at this step, though, and the order of the features in the GeoJSON file should match the order of the dragonfly Buildings in the dragonfly Model and that order of the HBJSONs output from the “To GeoJSON” component. When I get the chance, I’ll implement a step to pull the order of the output files from here so you don’t need to do these elaborate workarounds.
The Run URBANopt component will now return the result files in an order that matches how the HBJSONs are output from the GeoJSON component, which is also the order that the Buildings were added to the Dragonfly model.
Thanks @chris! I can say I walked into this group about a month ago and did everything the hard way instead of following all the directions. It is really something great to see how proactive and patient you and everyone else has been.