In my experience there is almost never a way around performing the intersections, and I often see newcomers trip over this step because they are unaware that it needs to be done, or myself simply forgetting it.
I may be incorrect; but the execution of the intersect solids script can be pretty computationally heavy; so having it be an ‘always on’ automatic process:
Personally I’ve tried it with ~400 something rooms, having intersect solids always on: It starts to g e t s l o w with a ton of rooms.
So every time the _input data in the Gh script was triggered via when I was creating new Rhino geometry; the int_solids was again triggered and it became rather tedious as any change to anything the geometry pipeline was picking up; it would have to re-run.
There was, in the same project; times where it was most effective to get a clean model by intersecting solids pre-solve adjacency in intentionally sequenced groups; otherwise intersecting the entire building’s rooms at the same time would raise errors in OS due to invalid geometry.
That may be part of it but I’m just assuming that may have something to do with it
Best @TrevorFedyna
Yeah, I think right now without parallel processing the Intersect Solids component checks intersection with every other geometry, meaning N geometries must perform the intersection check N^2 times, quadratic complexity.
Tangent: There are spatial indexing algorithms that recursively subdivide space so that you don’t have to search all geometries for intersection which reduces this down the search time to something like log(N), on average (if I recall correctly). To give an intuitive example, if you subdivide a 1D line recursively by two, then searching for any element in that 1D line is equivalent to a binary search algorithm, which takes log(N) steps to find an element.
That’s essentially the right answer, @TrevorFedyna . In addition to being computationally intense for large models, you also usually want to check the output of the intersection process before you go and create Rooms with it. Many times, there can be rooms that look like they are touching but they actually have small gaps between them and so no intersection actually happened. It’s much nicer to be able to bake, check, and edit these issues as Rhino geometry instead of working backwards from Honeybee objects (possibly running the solid geometry through the intersection component and baking a few times until it all looks good). Also, the HB Rooms component really would not be the right place to include an automated intersection calculation since you often have several of these components in one definition or you are using data trees, which will mean only certain groups of rooms get intersected with each other. Granted, we might consider putting something like this in the “Solve Adjacency” component at some point but this also comes with risks of having problems pass silently and people may not realize that something is wrong about their model until after the simulation has finished.
For @SaeranVasanthakumar 's point, there’s actually a much better way to scale this type of calculation that doesn’t need recursion and is already integrated into the LBT 1.3 “Intersect Solids” component. Just perform a bounding box check between two room volumes before you try to split one with the other. Bounding box checks are MUCH less computationally intense than intersection calculations and they can rule out most of the intersection calculations that would otherwise happen for a large model. In my experience, the bounding box check cuts down the intersection time by half for a 100-Room model and the savings over quadratic complexity usually become larger as the number of rooms grow. Also, for clarification, the calculation essentially runs the same whether you use one CPU or multiple CPUs. When run in parallel, the checking of each room against the others happens on separate threads rather than doing this one room after the other.
@chris, very good point, computing the bounding box intersection is indeed much cheaper then shape intersection, that’s why typically the recursive tree-based methods I mentioned store the bounding box, and not the polygon - best of both worlds! For example, here’s an explaination[1] of the typical workflow for using R-tree’s (spatial indexing via 2D tree subdivision) where the bounding boxes are used for a quick first pass for intersection checks. So you get the logarithmic search (O(logN)) to find neighboring polygons, plus the constant intersection complexity (O(2)) check for bounding box.
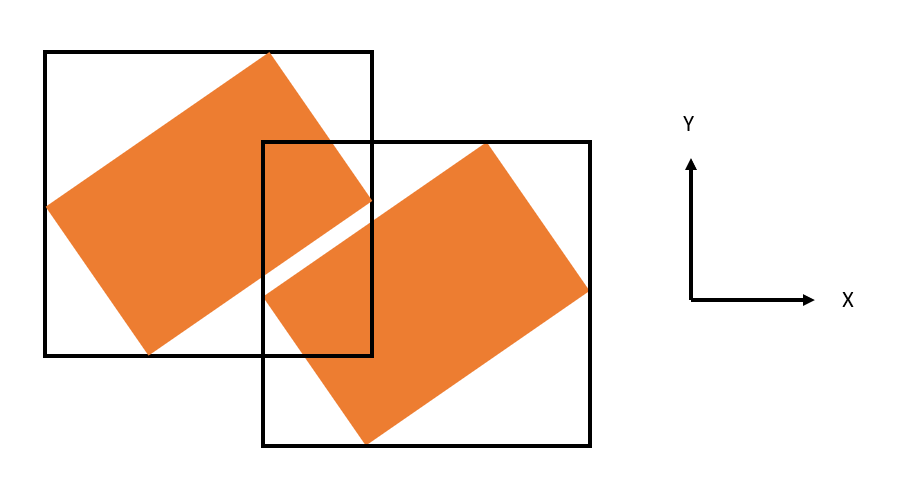
Tangent 2: This raises a third factor that I’ve been thinking about for a while: the orientation of the coordinate system can really contradict the efficiency of the bounding box calculation. For example, the image below shows a bounding box intersection in the typical coordinate system (standard basis):
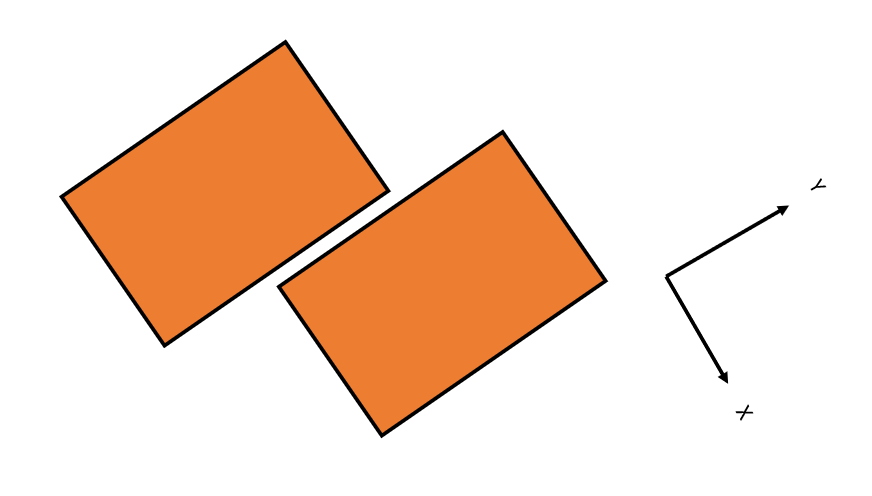
…But here you can see if you use a more natural, rotated coordinate system for this geometry, you get tighter bounding boxes and avoid the costly intersection calculation:
I suspect there’s a mathematically rigorous way to compute an efficient “rotation” to the coordinate system at the beginning of an intersection calculation. It relates to computing the eigenvectors of a statistical measure of your shapes called the covariance matrix. In english this means identifying the most prominent axis of a collection of datapoints. I think this is a superior way to store and compute spatial data… but I haven’t actually tested it yet so I could be totally wrong about it. There’s definitely some assumptions that need to be met for this to work.