I’ve been spending some time trying out the latest release of HB1.1. It is an excellent piece of work. I was using in the past DIVA4 and HB[+], this brought simulations to a new level. However, there is something that I don’t understand with the new calculation method.
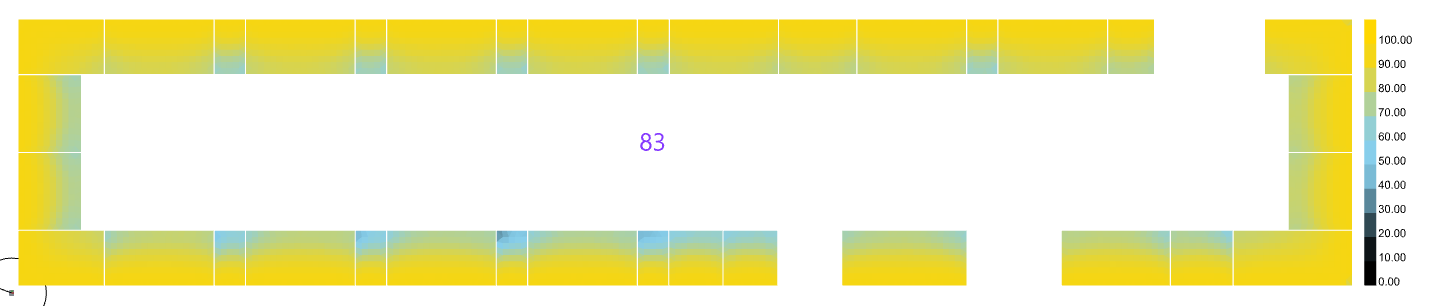
The image below shows an example of the speed difference for a relatively simple model. 26 min in DIVA vs 4 min in HB1.1, with very similar results (small model differences)
This is a reduction of 85% of the simulation time, which is fabulous! However I was thinking that if I connected HB1.1 to accelerad, I could bring the value even further lower. It turns out that I managed to reduce the speed from 26 to 10 minutes, which is nice, but way slower than the standard HB1.1.
Granted, I’m not familiar with the changes in HB1.1, but noticing that your illustration has a separate legend for each room, is it possible that HB1.1 is running each room as a separate simulation? Accelerad doesn’t like running multiple instances simultaneously, as that would require the GPU to constantly switch context, which slows the whole thing down. If that is what’s happening here, then try running this with Accelerad without multithreading. Given the number of points involved, it’s probably also a good idea to set Accelerad’s -ac parameter to the number of sensor points.
Thanks for the prompt reply. That is definitely not happening, HB1.1 is splitting the entirely of points to be calculated in groups of 200 points, which then are cyclically being calculated using all the available cores. (10.000 points => 50 mini simulations of 200 points)
That is the difference between the DIVA and the Legacy approach, which was dividing the points in the beginning of the simulation by the number of cores, and the final calculation would always be equal to the slowest of those parallel runs. (10.000 points / 10 cores = ? 10 simulations of 1000 points)
Combined to the fact that HB1.1 ditches DAYSIM, this is my interpretation of the incredible increase of speed while keeping the same results.
Concerning Accelerad, I saw that the calculation was using GPU very intermittently, which could be because of the really short calculation time, but then it spent way too much time stuck in rtrace.
I will try to play with the accelerad settings, especially the -ac, to see if it works. I will also try to compare HB1.1 with and without accelerad in single core. That should be quite a difference.
edit: now that I read my reply I see that you must be right in the fact that accelerad doesn’t like mutiple instances. I should be able to find out the differences in single core. I’ll report my findings as soon as I have them.
It turns out you were right Nathaniel. HB1.1 is dividing the simulation per grid. I rerun the simulation as a whole and here is the final result, with a total run time of 2 min!
With that out of the way, the question now is: how we can group all the grids for the simulations and ungroup them at the end for data processing of individual rooms?
you can explode your mesh and use the unflatten component in grasshopper to make the mesh faces align with the structure of your rooms… Then join together the pieces again. Remember only to preview the joined meshes and not the single faces as that will lag.
I just tried to simulate a small part of a hospital with 60+ rooms. After 5 minuttes i cancelled the simulation (was using low settings and 3ab just for a quick test), and merged all the simulation points to one hb_grid. Now it finishes in 10 seconds >_<
Definately looks like there’s a lot of overhead done per grid.
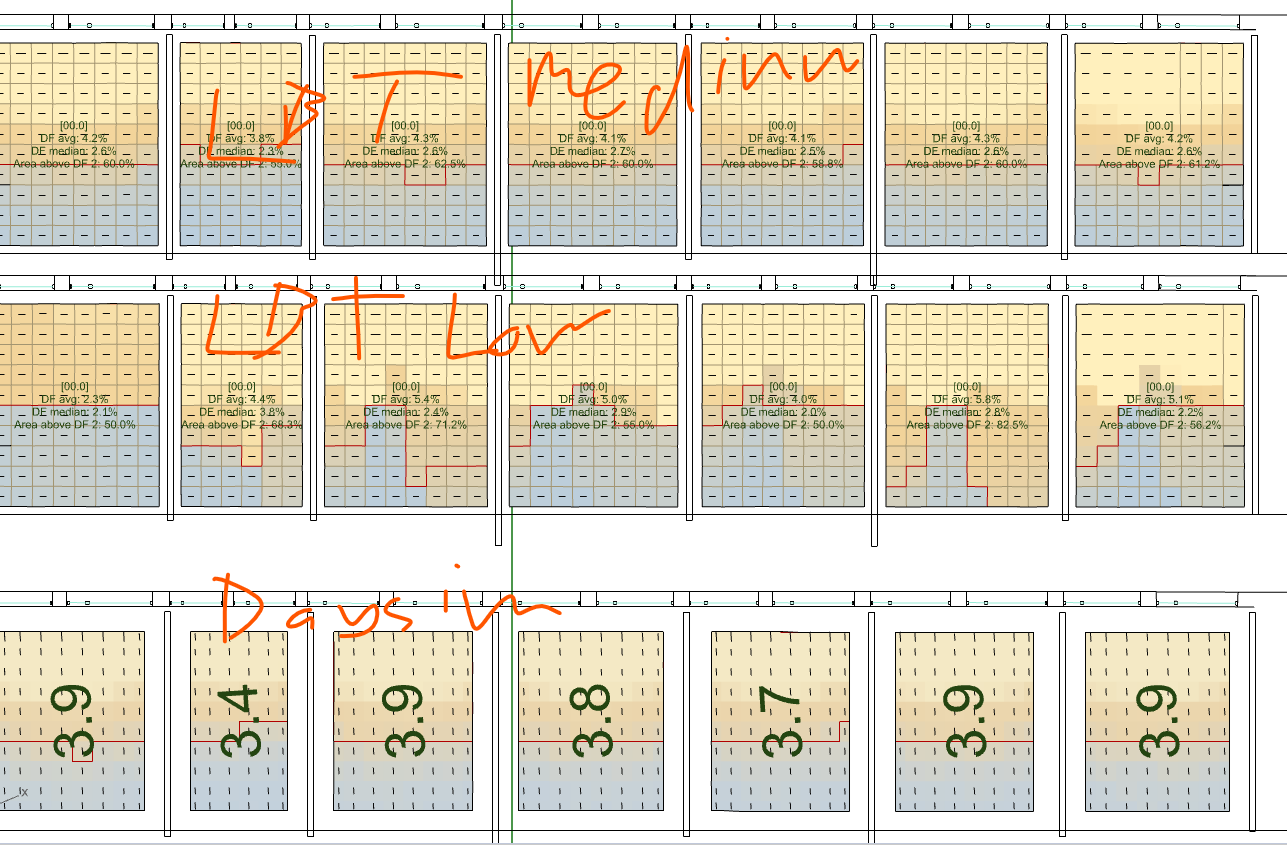
Btw did compare the low setting in LBT with the low in legacy. There was some differences. However setting LBT to medium gave me similar results to low in legacy/daysim.
See attached comparison.
Daysim/legacy was on low.
All of the three simulations were with -ab 3. (Although I usually run much higher…)