Please forgive me if I’m knocking on the door a bit early…it’s more out of excitement than impatience
In future developments of HB Radiance, is there a plan to integrate the writing of cases prior to running the cases (same as for HB+)? I’m asking this with in mind to execute manually multiple cases at the same time and dispatch my computer power.
We are in the process of refactoring the HB-Radiance recipes at the moment but, once we are done, you will be able to write your Models to a HBJSON (or possibly a Honeybee-Radiance Folder) and you’ll be able to plug those files/folders into the recipe components (instead of just plugging in the Honeybee Python object). This way, you can write out all of your models to files/folders first and then execute them each separately.
… or you’ll be able to upload those Model JSONs to our Pollination cloud service once we start selling subscriptions in another few months. We’ve been doing some initial tests with up to ~100 CPUs and we’ve been able to get some simulations to run in roughly 1/10th the speed of our most powerful desktops. So I believe the excitement is merited.
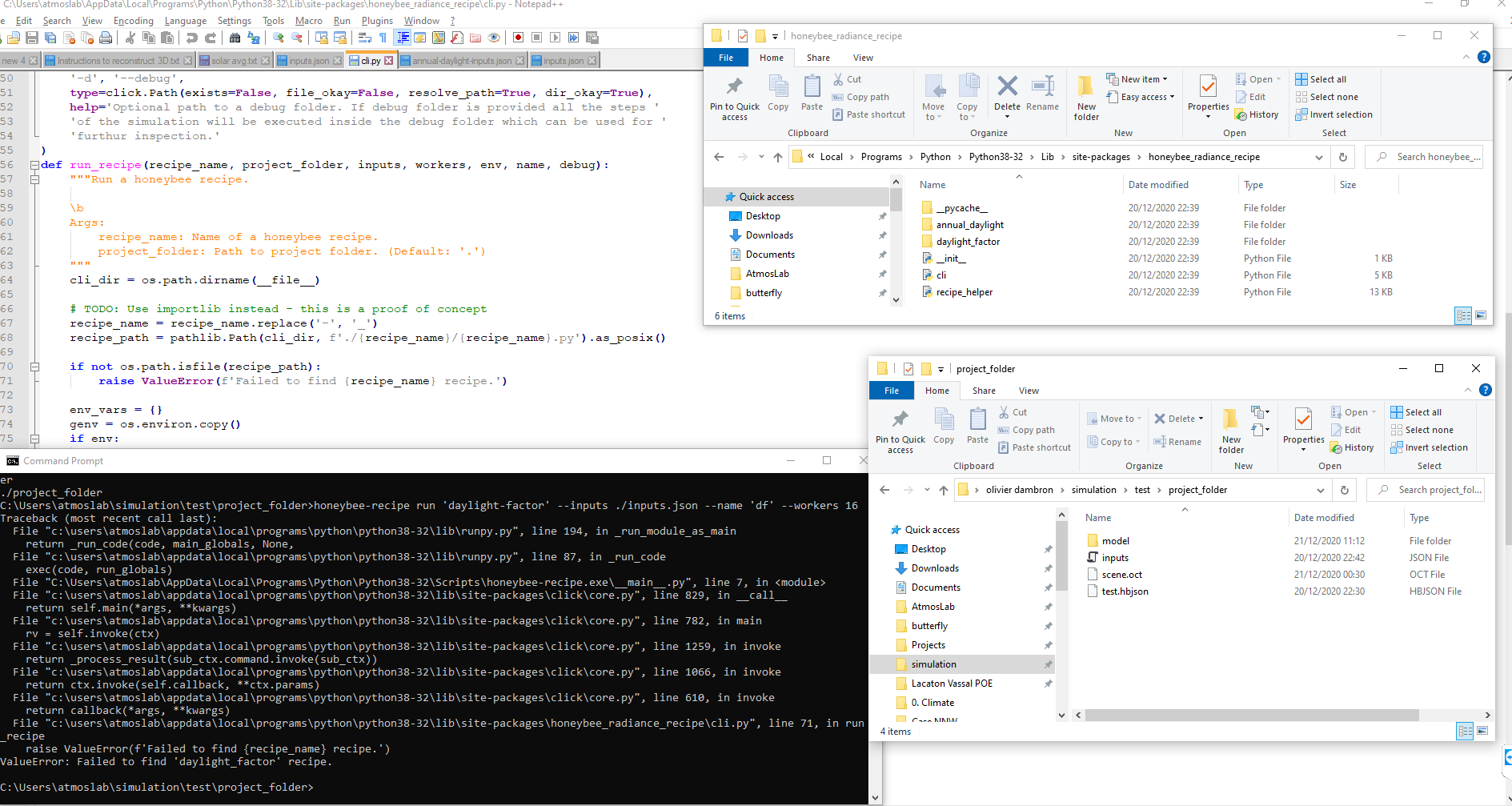
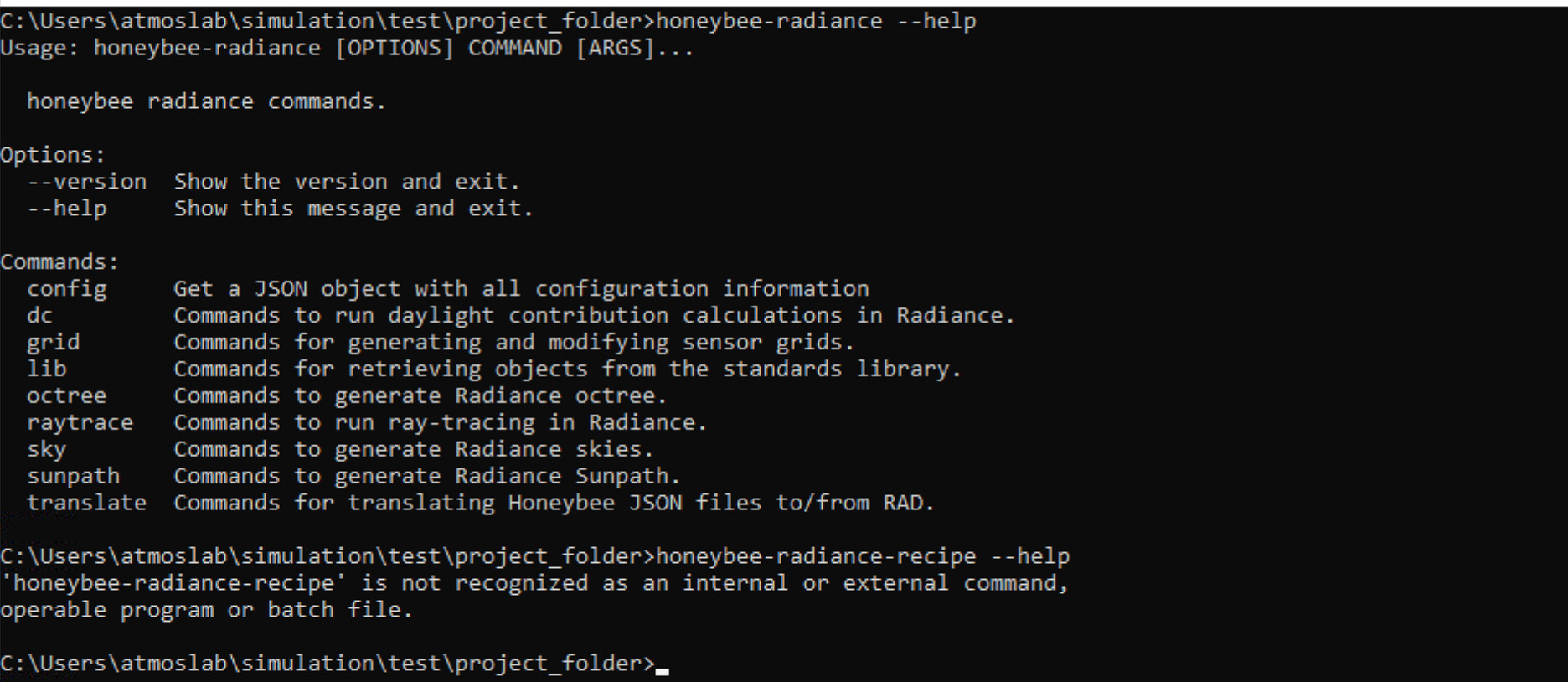
OK for honeybee-recipe. I can now see it is installed.
The problem of not finding the recipes still occurs with the following command (same for annual):
“honeybee-recipe run ‘daylight-factor’ --inputs ./inputs.json --name ‘df’ --workers 16”
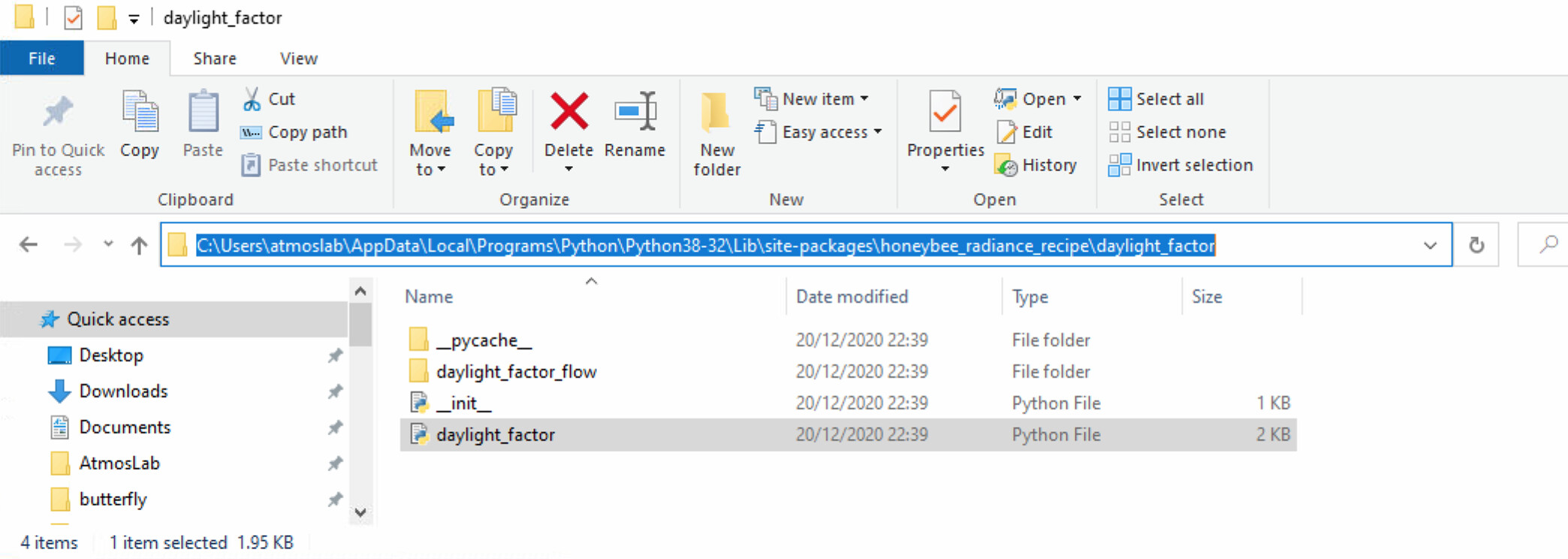
Yes there is a daylight_factor.py in the package installation folder.
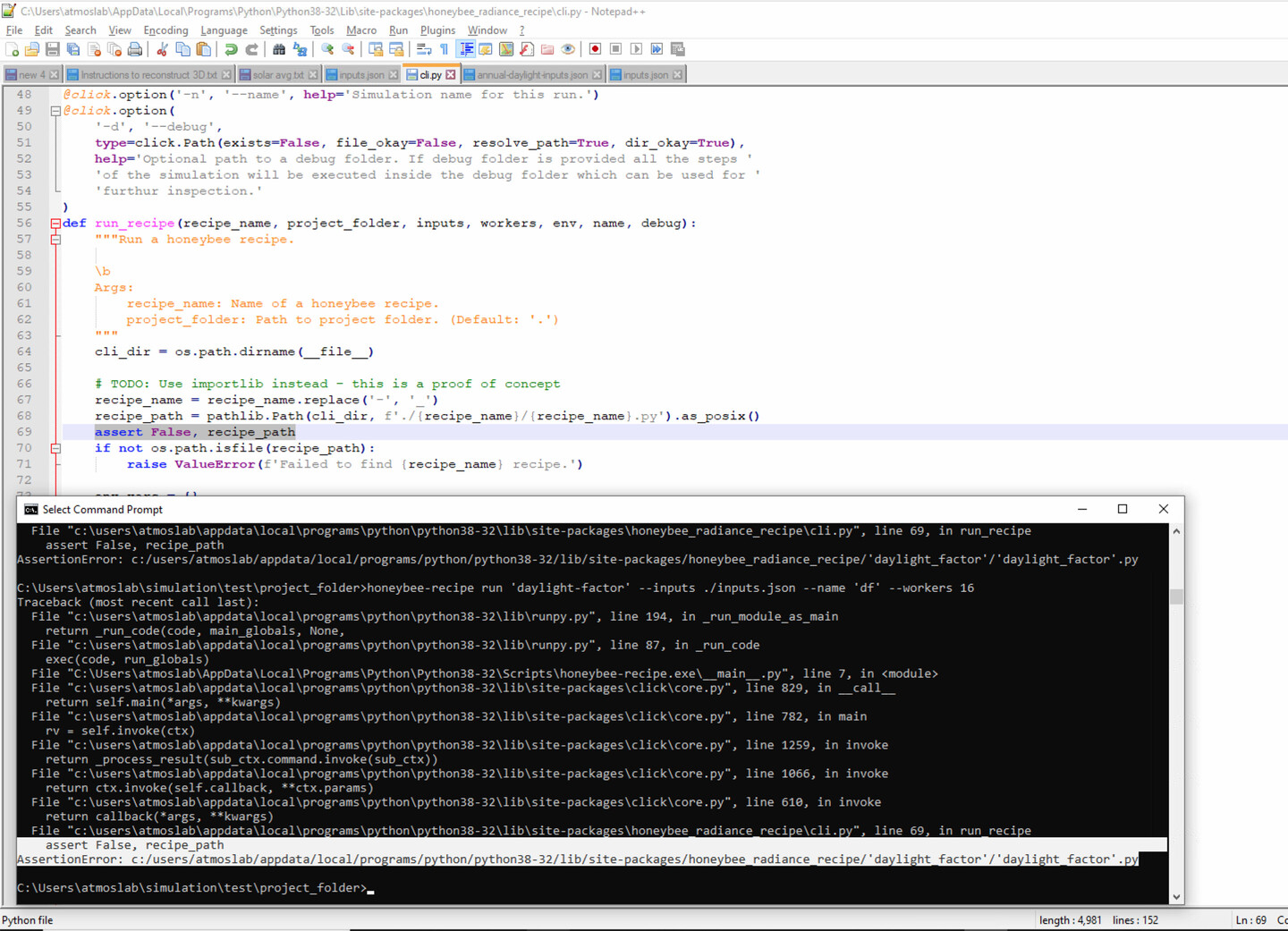
I see! The quotes are the issue. I was testing it on powershell and linux not CMD on Windows. I belive either of these options should work. If the first one works on Windows then we can just use that everywhere.
honeybee-recipe run daylight-factor --inputs ./inputs.json --name df --workers 16
or
honeybee-recipe run "daylight-factor" --inputs ./inputs.json --name "df" --workers 16