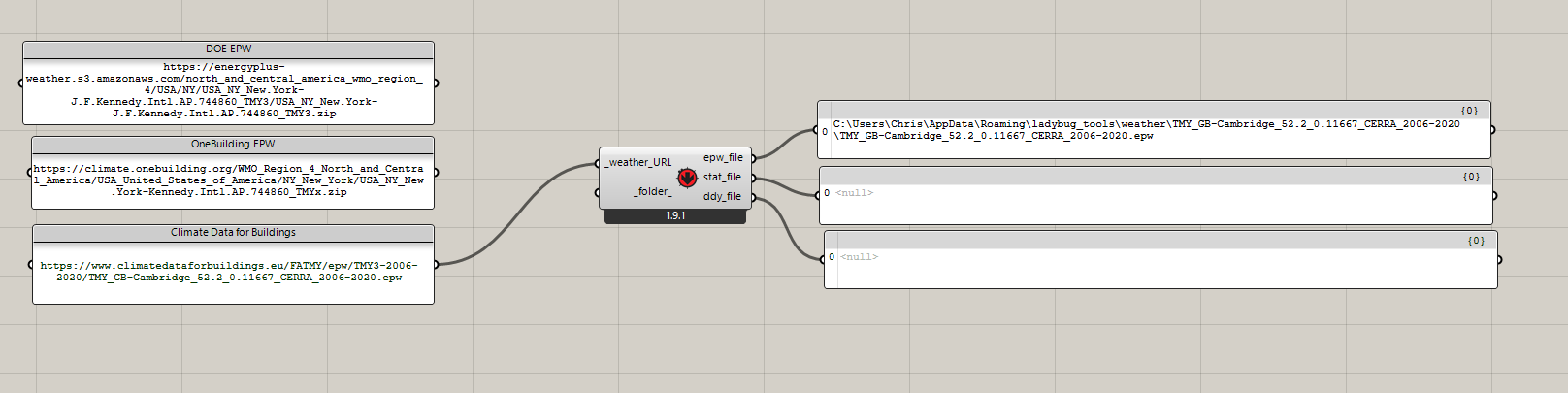
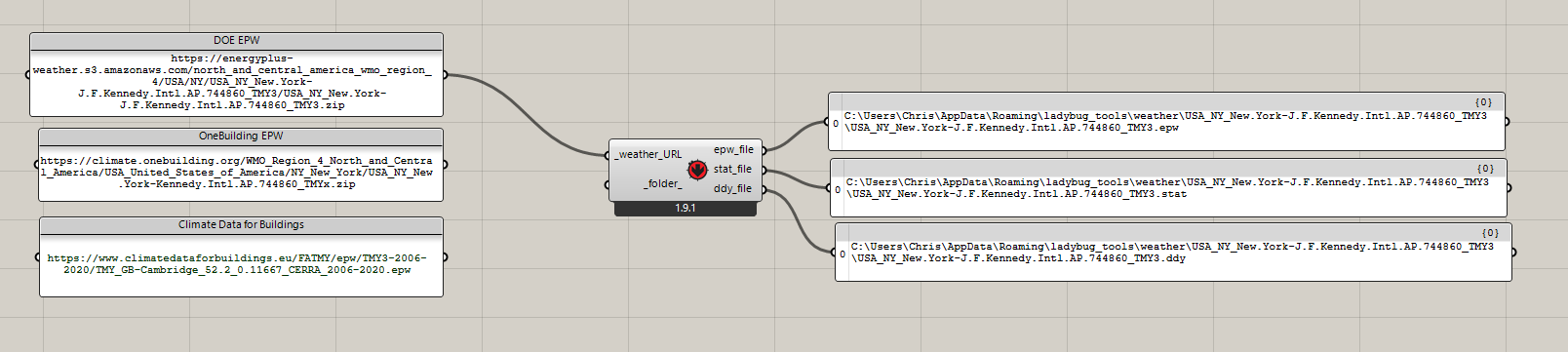
Hi.
I am wondering if it would be possible to modify LB Download Weather, so that it is also usable to download epw files from locations that have .epw files directly.
It only requires two minimal changes:
-
detect if url ends with .epw and set folder name
elif _weather_URL.lower().endswith('.epw'): _folder_name = _weather_URL.split('/')[-1][:-4] -
skip unzip, if url ends with .epw
if _weather_URL.lower().endswith('.epw'): download_file(_weather_URL, epw, True) else: download_file(_weather_URL, zip_file_path, True) unzip_file(zip_file_path)
The total code block would then become:
```
if all_required_inputs(ghenv.Component):
# process the URL and check if it is outdated
_weather_URL = _weather_URL.strip()
if _weather_URL.lower().endswith('.zip'): # onebuilding URL type
_folder_name = _weather_URL.split('/')[-1][:-4]
elif _weather_URL.lower().endswith('.epw'): # NEW: direct EPW URL
_folder_name = _weather_URL.split('/')[-1][:-4]
else: # dept of energy URL type
_folder_name = _weather_URL.split('/')[-2]
if _weather_URL.endswith('/all'):
repl_section = '{0}/all'.format(_folder_name)
new_section = '{0}/{0}.zip'.format(_folder_name)
_weather_URL = _weather_URL.replace(repl_section, new_section)
_weather_URL = _weather_URL.replace(
'www.energyplus.net/weather-download',
'energyplus-weather.s3.amazonaws.com')
_weather_URL = _weather_URL.replace(
'energyplus.net/weather-download',
'energyplus-weather.s3.amazonaws.com')
_weather_URL = _weather_URL[:8] + _weather_URL[8:].replace('//', '/')
msg = 'The weather file URL is out of date.\nThis component ' \
'is automatically updating it to the newer version:'
print(msg)
print(_weather_URL)
give_warning(ghenv.Component, msg)
give_warning(ghenv.Component, _weather_URL)
# create default working_dir
if _folder_ is None:
_folder_ = folders.default_epw_folder
print('Files will be downloaded to: {}'.format(_folder_))
# default file names
epw = os.path.join(_folder_, _folder_name, _folder_name + '.epw')
stat = os.path.join(_folder_, _folder_name, _folder_name + '.stat')
ddy = os.path.join(_folder_, _folder_name, _folder_name + '.ddy')
# download and unzip the files if they do not exist
if not os.path.isfile(epw) or not os.path.isfile(stat) or not os.path.isfile(ddy):
if _weather_URL.lower().endswith('.epw'): # NEW: direct EPW download
download_file(_weather_URL, epw, True)
# OPTIONAL (still minimal): try to fetch matching stat/ddy if present
# If you don't want this, delete the next 6 lines.
try:
download_file(_weather_URL[:-4] + '.stat', stat, True)
except Exception:
pass
try:
download_file(_weather_URL[:-4] + '.ddy', ddy, True)
except Exception:
pass
else: # existing ZIP flow
zip_file_path = os.path.join(_folder_, _folder_name, _folder_name + '.zip')
download_file(_weather_URL, zip_file_path, True)
unzip_file(zip_file_path)
# set output
epw_file, stat_file, ddy_file = epw, stat, ddy
```