I am working on a definition that takes GIS data(SHP & CSV) to generate a 3d model, then feed it to LB/HB for various simulations. I am dealing with a large number of datasets in both SHP and CSV formats, so it is not practical to relocate them close to the origin. I am aware of the issue with geometries far from the document origin, and I have been searching for the solution with no luck. Has anyone found a solution to the issue?
Thanks for the reply. I tried it a while ago, but it didn’t work. As far as I understand, setting a new origin doesn’t really move the document’s origin. Any other thought?
How are you attempting to move the geometries to origin? It should be a trivial…
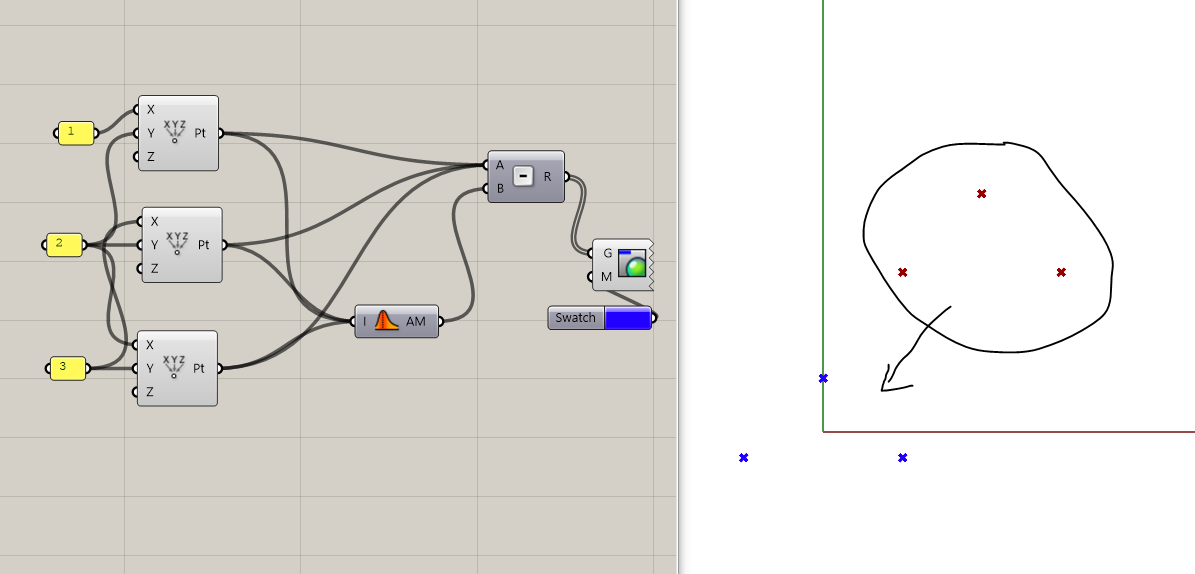
For a collection of geometry points, find the average <x_{avg}, y_{avg}>, then subtract that average from all your points. Since the points are vectors in Rhino, you can just use the math components directly for this:
Thanks for the suggestion.
That is what I am doing, but it just takes so much time in processing hundreds of thousands of lines of CSV and SHP poly-lines. I wonder if there is any global approach to simply relocate Rhino document’s origin, but what minggangyin suggested above doesn’t work with LB/HB. So I naturally am curious if there is any way to do it LB/BH.
If the model is too large for vector addition and subtraction, I think your simulation time is going to be enormous, to the point of impossibility in Grasshopper. The cumulative geometry operations used in Ladybug are a lot more costly then centering points.
I agree with @minggangyin’s, it’ll be helpful to see the size of this model. Thinking of ways to abstract your model to a representative subset of your geometry may be a better way to resolve your issue.
Calculating the bounding box still requires going through all the points. You have to go through all the points and find the maximum and minimum x and y coordinate by checking every point in the dataset: bbox_{midx}, bbox_{midy} = \frac{max(X) - min(X)}{2}, \frac{max(Y) - min(Y)}{2}
Given n datapoints, algorithms that require going through every single datapoint are said to have linear time complexity (denoted as O(n)). This is actually considered very efficient! For comparison, in a worst-case scenario something like the surface-adjacency algorithm used in Ladybug can have quadratic time complexity O(n^2), every operation is run n \cdot n times (but on average it should be less). That’s why I think if moving points to an origin is too costly, the size of the dataset is likely to cause issues downstream.