Hi everyone, I am currently conducting a study on the correlation between urban building form and outdoor comfort. I am using LB+HB version 1.5 combined with Colibri plugin to generate different urban form models by batch sampling urban form parameters and calculating the corresponding UTCI values.
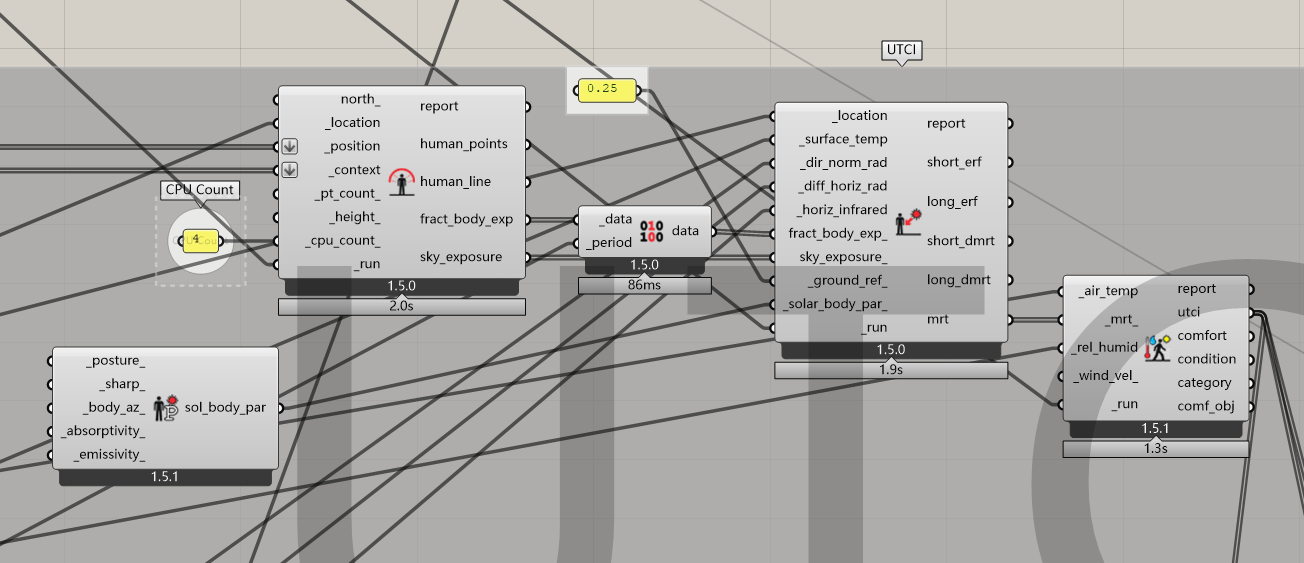
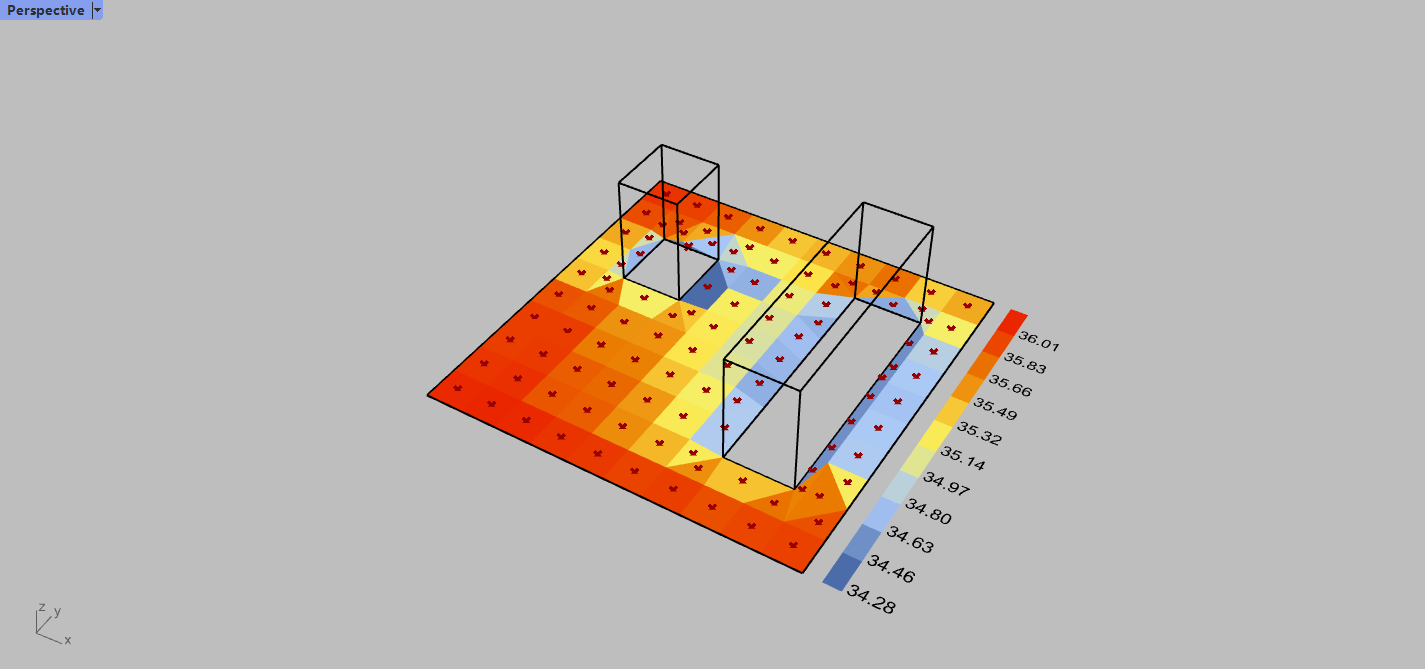
I use HumanToSky, OutdoorSolarMRT and LB_UTCI to get the UTCI value as below.
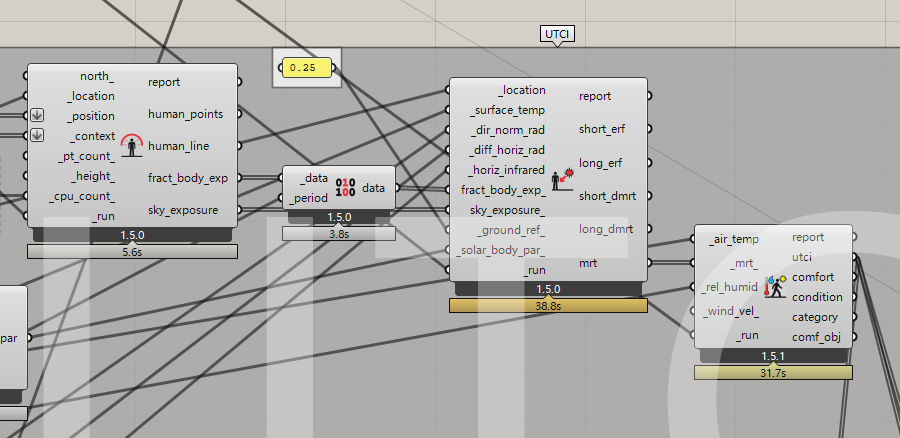
I found that the computation time of UTCI became significantly longer after hundreds of iteration. For a simple city block model, the first run took only a few seconds, but by the 500th run, its total computation time could reach almost one minute. I guess it is because during the iterative computation, the program stores some data temporarily and iterates through the existing data generated by the previous runs in the subsequent runs.
How can I solve this issue? I think it’s a complicated thing.
It doesn’t look like this issue is caused by Colibri. I also encountered this today, when I tried to use the wallacei plugin for UTCI optimization. I analyzed the OutDoorSolarMRT and LB_UTCI modules and found that they only involve polynomial calculation, so I still can’t explain the increase in calculation time with the number of runs, so hopefully @chris can examine the code to find out if this is only happening on my computer or if it is a common occurrence.
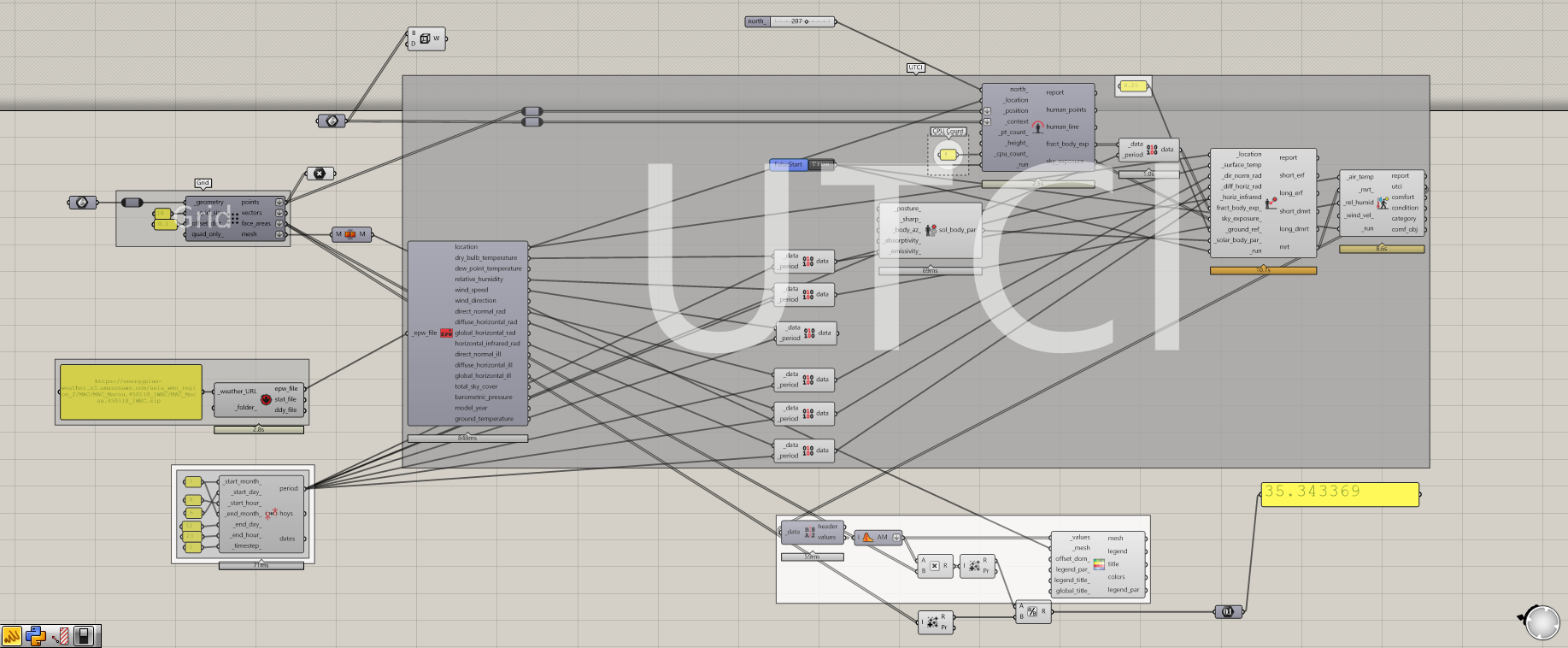
This is a simple model to calculate UTCI of one week in summer. I use one slider to change the North. To test the running time, just animate the slider from 0 to 100 (not too large number, or you will need hours of waiting.)
The first round, the UTCI value will appear in 3 seconds, after several rounds, the time increases. UTCI_Testing.gh (59.5 KB)
Hi @miraclema, have you looked at your RAM usage? If you’re storing all the results in your script (or if grasshopper is doing that for any reason) then once your RAM is full everything will probably slow down considerably.
Iterating a model lots of times is likely creating a new python object each time which I would guess will fill up your RAM if you’re making lots of models. From what I know of the code in the components and on the backend I can’t see the LBT changing this as duplication / creation of multiple python objects avoids issues arising in much simpler use cases.
The simulation is on a workstation with 96GB RAM and 32 cores, so I suppose it’s not about the RAM. During calculation, I can see one of the cores keep running 100%.
With 96GB RAM I’d be surprised if that is the issue - what does your RAM usage reach when you get to around iteration 500-600 out of interest to rule that out?
Grasshopper does lag a lot when lots of data is being stored on a canvas, I’m not entirely sure why, but if you’re storing data from each iteration in grasshopper somehow then that could be causing the slowdown - I’m not sure what the reason for that is though.
The file is small, so I think this issue must be something we dont know…
I decide to copy all the relating core code into one component of grasshopper, to test whether it can affect calculating time.
Thanks for answering the question, @charlie.brooker and you came to the correct conclusion.
It’s an issue that is deep within Grasshopper and has something to do with way that it keeps stuff in memory as iterations happen. It occurs whether the iteration is done with the native Grasshopper “Animate slider” method, Colibri, or some other plugin. The issue typically gets worse the more iterations of a computationally intense script are performed such that somewhere around 1,000 energy simulation iterations, Grasshopper will typically crash. In the past, I have tried debugging it with David Rutten and we were not able to come to a conclusion about it. But, honestly, the fact that Grasshopper offers the ability to run so many computationally intense iterations and remain stable is pretty impressive (certainly better than some other visual scripting interfaces that I know).
My suggestion to @miraclema would be to do the following:
Use the UTCI recipe in HB-Energy, which offloads the ray tracing simulation to Radiance instead of your current Ladybug workflow that runs all of the ray tracing computation within Rhino/Grasshopper. Being able to offload the computation from the Grasshopper instance is definitely going to cut down on the amount of memory used with each iteration to let you run larger design spaces. Also, the Honeybee UTCI recipe is more accurate than your current method since it can account for shortwave solar reflections.
Break up your simulations up into chunks, maybe running 700-800 at a time if you are using the recipe above or 200-300 if you are using the Ladybug components. Restart Rhino in between simulations of chunks.
If you are willing to just generate all of the input files in one Grasshopper script and then use another Grasshopper script to simulate them, I have found that this typically lets me run much larger design spaces without crashing or getting slow. For example, I could easily get up to 4,000 energy simulations this way back in the day and the practical limit of this is probably somewhere in the tens of thousands of simulations since just writing files is not very taxing on Grasshopper memory.
The reason why I say “back in the day” above is because I would use Pollination could computing to do this in today’s world, which benefits both from the fact that we’re only writing out files locally as well as the fact that you can get 600 CPUs running the simulations on the cloud if you’re using the Professional version. Granted, I know I’m plugging our cloud service here, which is not free, but it is the ultimate answer to how to run very large parametric studies that involve simulation.