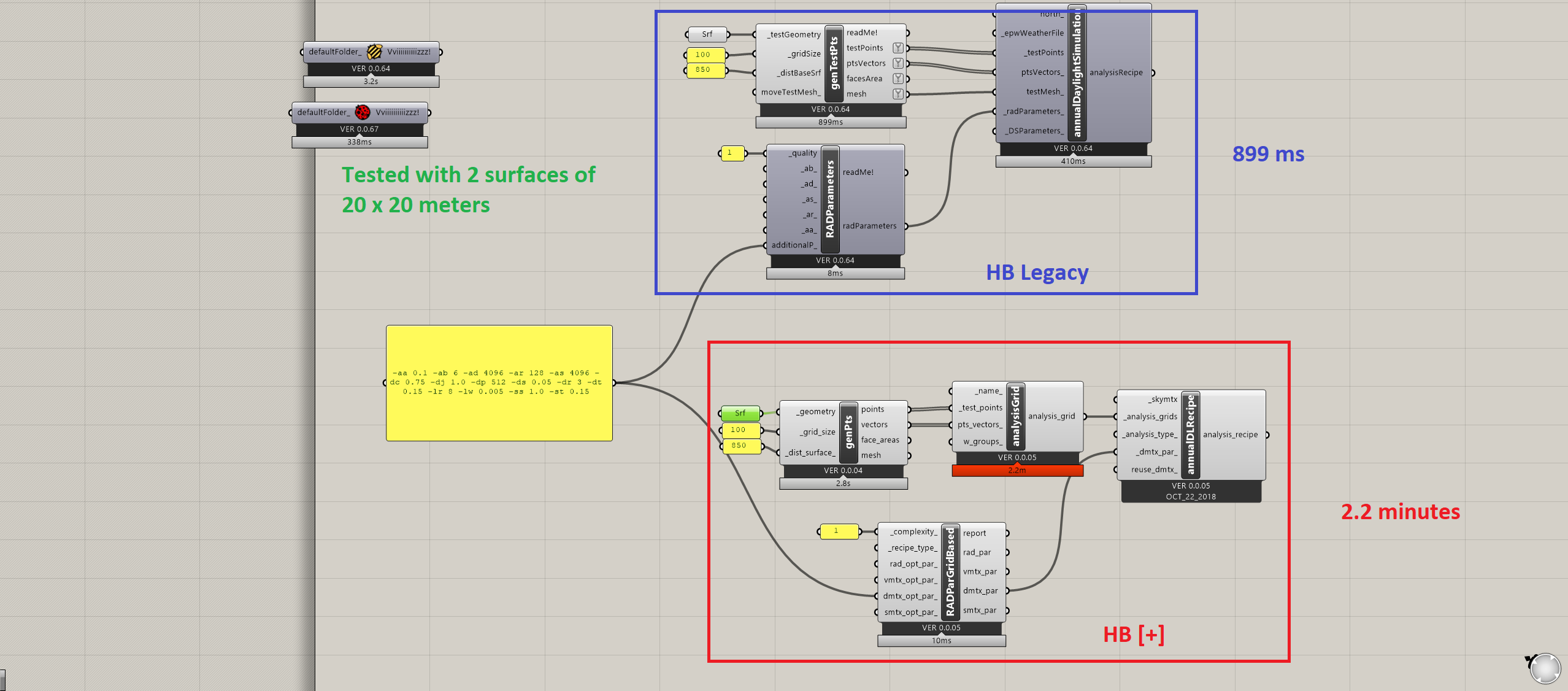
Why is it that generating a lot of test points in the analysisGrid component from HB [+] takes a lot longer time to compute than the similar HB legacy component GenMesh?
This is especially notable when connecting the analysisGrid to the HoneybeePlus_Annual Daylight Recipe module.
@C.Bech You should post some screenshot for this question. If you can upload the rhino model and grasshooper definition, it will be nice for this discussion.
@minggangyin
You are right I uploaded the GH file as well as an attached image. This test is made with a very simple surface of 20x20 meters. A HB [+] computation time of 2 minutes might not seem as much but a relative comparison to Honeybee Legacy show quite a significant difference in computation time.
This is a known issue and is going to be addressed with AnalysisGridLite which is already implemented in source code but hasn’t been ported to the Grasshopper plugin:
Here is the longer explanation:
In the current implementation AnalysisPoint carries all the results for that point. This means you can call methods like AnalysisPoint.annual_metrics directly from the point which is handy and in my opinion how it should be. The implementation works just fine in Python - but it becomes very slow in Grasshopper. I was unable to figure out what exactly happens but for any reason it became a major performance issue in Honeybee[+].
To address this issue we have broken down these two responsibilities into two separate classes. AnalysisPointLite only carries the position and direction of the point and the results will be loaded to a Sqlite database. There is a ResultCollection class that handles the calls to database so we can get a high performance without overloading Grasshopper.
Now you are probably thinking why it has not made its way to Grasshopper if the issue has been solved. The answer is that we are overhauling the way the studies are undertaken with Honeybee[+]. See:
Thanks a lot for the elaborated explanation of the observation, and I think you are right and have found a good compromise by dividing the component into two separate classes.
Overhauling Honeybee[+] must be hard work - wish you good luck, and thank you for your the great work so far.