I’ve tried reading a lot of previous posts concerning radiance parameters, but haven’t found an answer to my question yet.
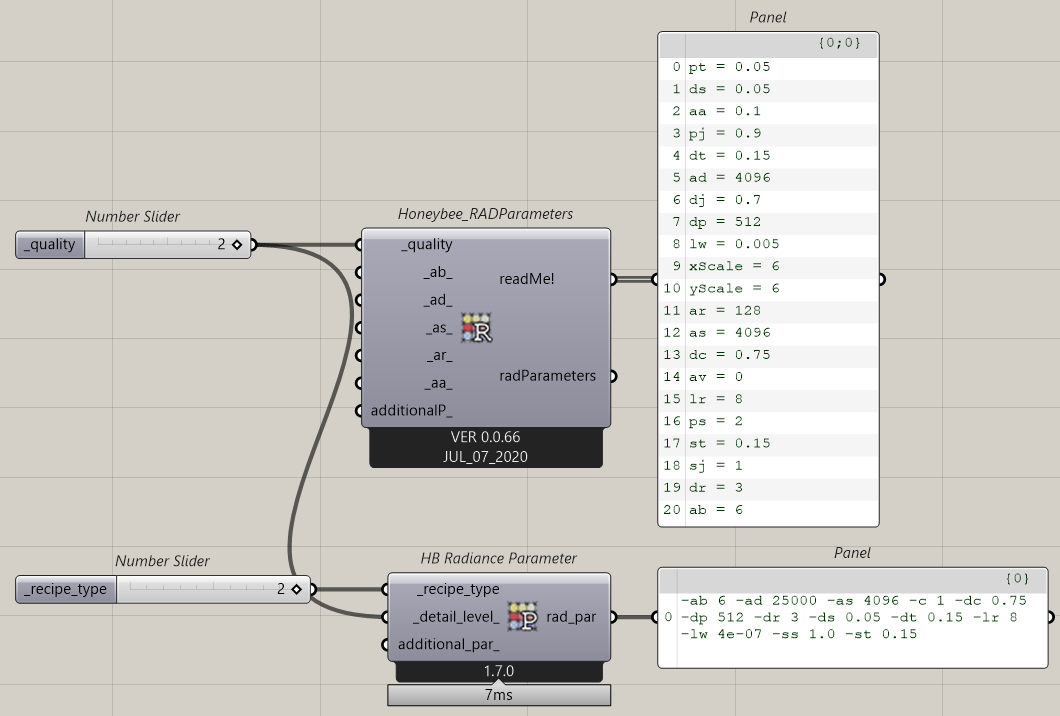
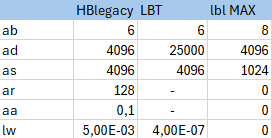
I have noticed that the recommended Radiance parameters in the new HB Radiance Parameter component in LBT is different than thos suggested in the previous Honeybee_RADparameters from HB-legacy. I have summarized the parameters in the table below to make a better overview.
From the post below I understand that -lw is calculated as lw = 1/(ad*100) to “avoid splotches”
But why is the recommendation for -ad so much higher in LBT?? The values above are for high quality, but the -ad is also much higher when using lower quality level in the HB Radiance Parameter component. Should this -ad also be used in HB-legacy or has there been made changes in the calculation method from HB-legacy to LBT?
Posting mainly because I’m interested rather than because I can effectively answer the question!
I think @mostapha is likely the person closest to the answer, although I’m sure @mikkel will also have insight.
Here’s an interesting tool I like to show people related to setting different parameters
And if you look at the source code for the rad parameters component you’ll see it’s only rfluxmtx that has the higher -ad input. The other methods do match (at a glance) the radsite recommendations.
You are on the right path. The source of the parameters is the suggested parameters for rpict that @charlie.brooker provided a link to. Those parameters were useful for legacy since we were using Daysim which uses rtrace under the hood.
The new plugins use rfluxmtx and rcontrib for annual studies which makes the behavior different. In particular there is no caching anymore.
The final values that we used was based on the sensitivity analysis that @sarith ran, and you can see them in the link that @charlie.brooker linked above and I’m resharing here.
In short, there is no single correct value. We just used our best judgment to come up with what we thought could be reliable for most of the models.