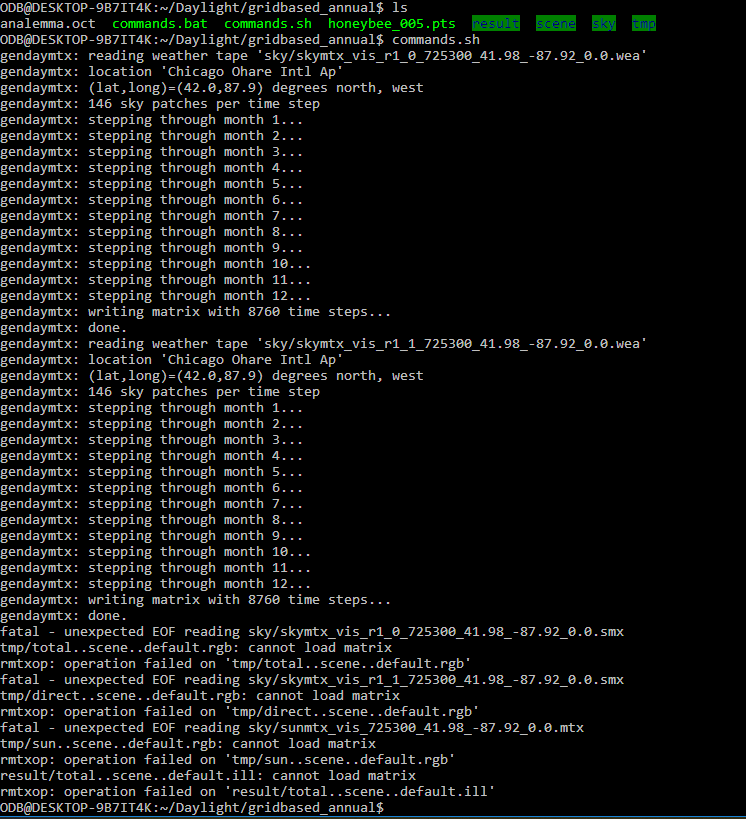
I am writing HB[+] cases and trying to run all commands manually of the commands.bat to further dispatch onto multiple CPUs.
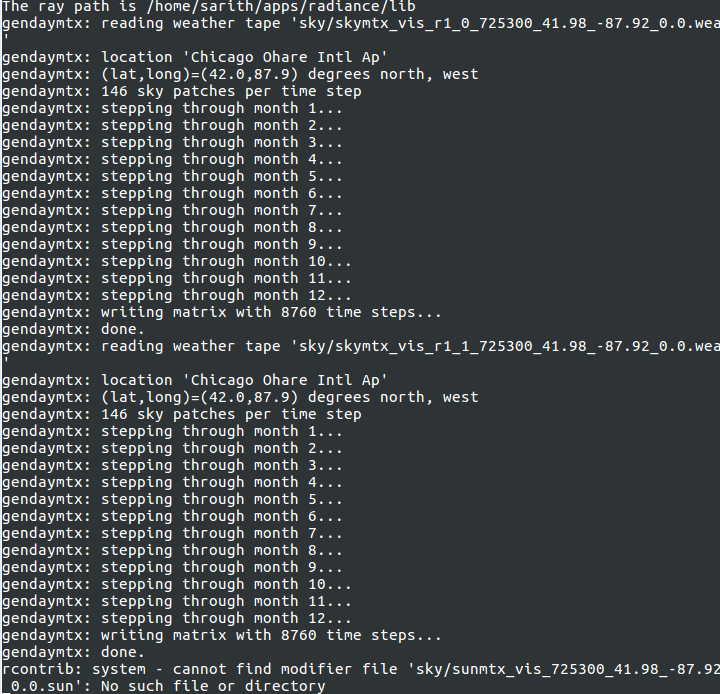
Gendaymtx works well but then dctimestep returns a fatal error:
Hi Olivier, I thought a while ago @mostapha wrote a direct convertor from bat to sh. That should let you convert the script automatically.
Anyway, can you share/inbox the files ?
Thanks for the prompt reply. I am testing it with the annual recipe sample case and replacing this edited commands.bat where I’ve replaced the backslashes to frontslashes.
I was planning to divide my test surfaces onto as many cases as there are of CPUs. Is this as good as using the -n commands to parallelize as @mostapha suggested here
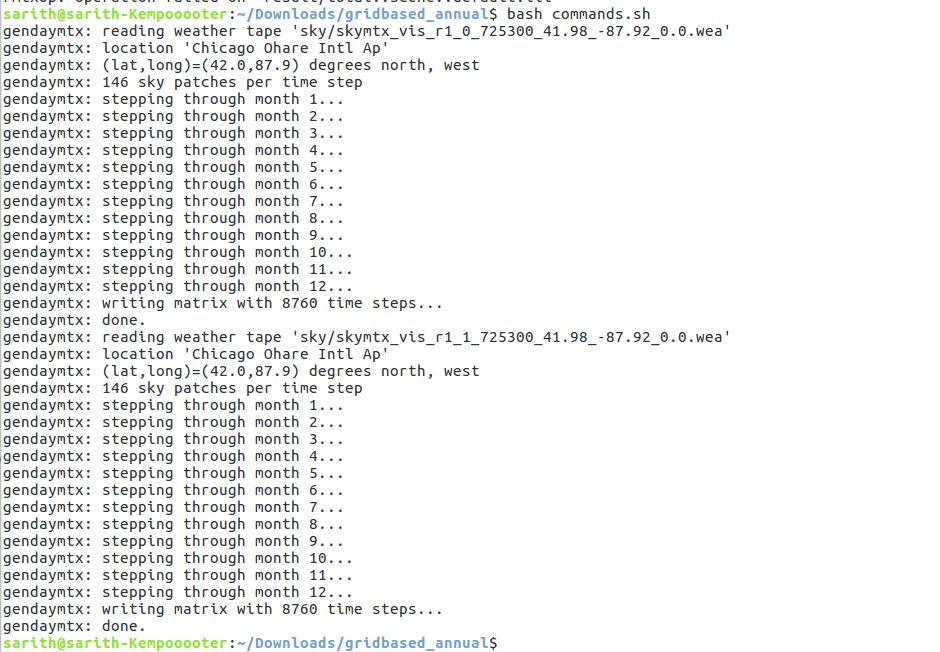
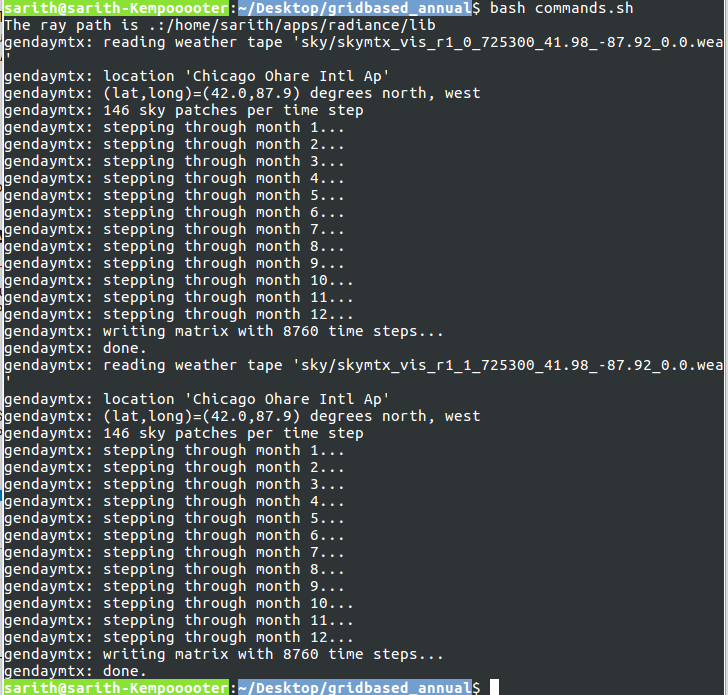
Can you try the attached shell file and see if it works. You need to copy it inside the project directory and then run it through bash (the same way as you were running previous commands). And don’t open and close this file on Windows!.
I think the issue is with the \r carriage return added by Windows to the batch files. This one should work.
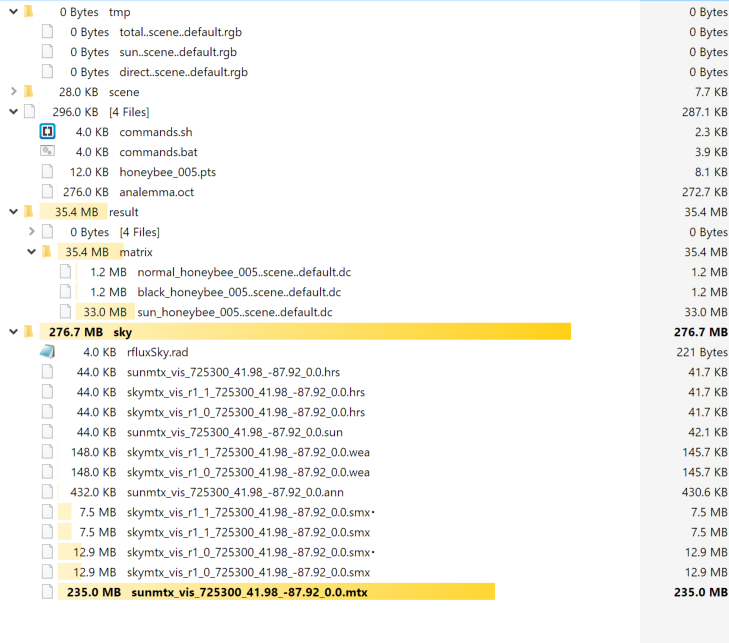
Which OS are you running. And are you getting any zero kb files in any of the folders?
One other thing, which version of Radiance are you running on your Linux system. A rcontrib -version will tell you.
So your coefficient matrices and sky matrices are getting created fine and the sizes are comparable to what I got. For whatever reason dctimestep is not able to load the results from either rcontrib or gendaymtx and that is causing a cascade of failures downstream.
I am not sure if the Radiance version that you downloaded is compatible with bash for windows. I recently had to compile Radiance from source on a Raspberry Pi as the NREL version was crashing (even though Pi runs a flavor of Linux). One possible to way to test this would to run the calc on a Ubuntu VM through Virtualbox or something similar.
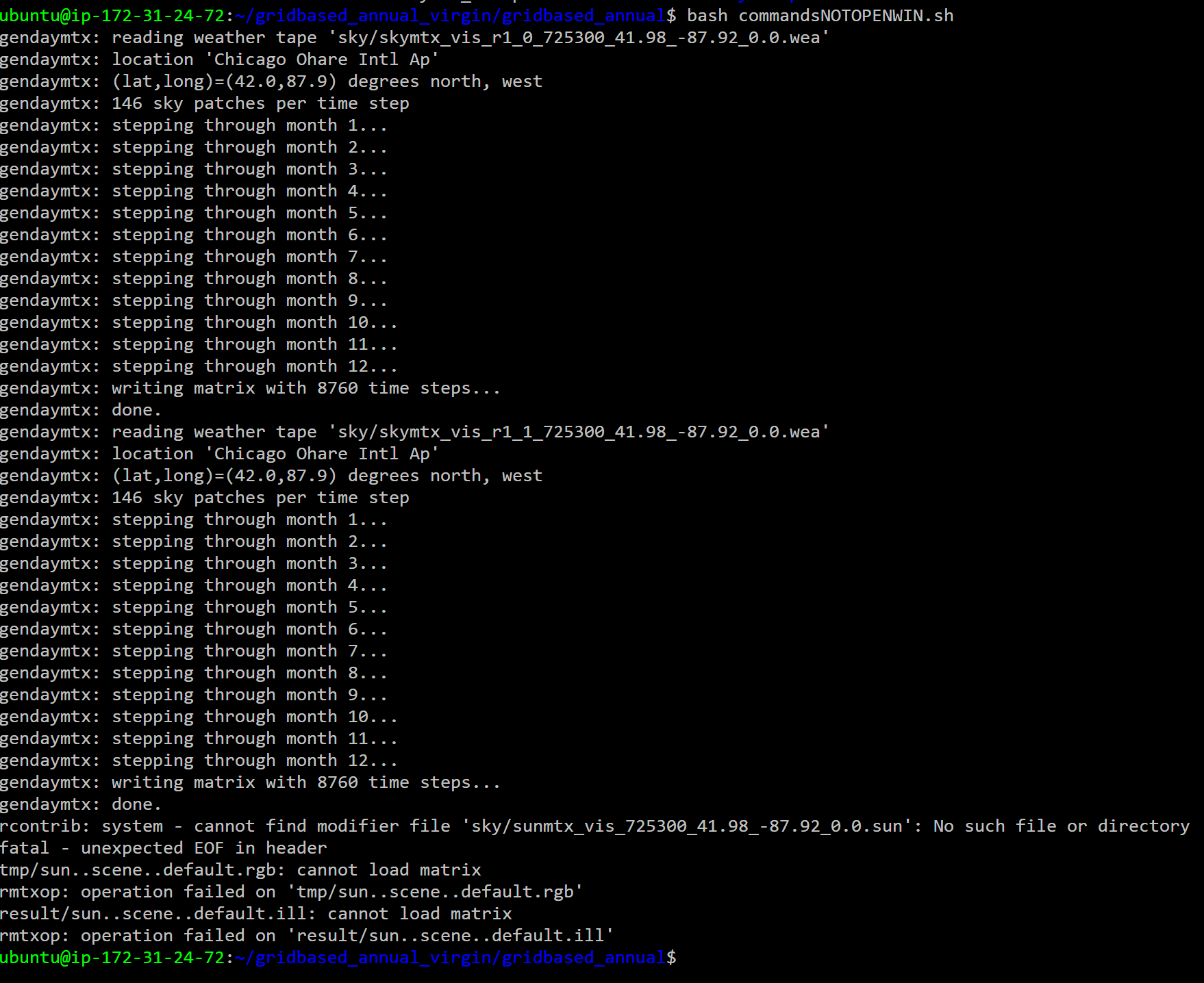
I’ve launched an EC2 instance with Ubuntu 16.04, installed radiance from the latest release on the NREL repo. Set the RAYPATH and PATH in the .profile by adding:
set a RAYPATH if this environment variable does not exist
if [ ${RAYPATH:-""} = “” ] ; then
RAYPATH=/usr/local/radiance/lib
export RAYPATH
fi
add the radiance binaries to the PATH (note we added at front of path)
PATH=/usr/local/radiance/bin:$PATH
set a MANPATH environment variable if it doesn’t exist
if [ ${MANPATH:-""} = “” ] ; then
MANPATH=/usr/share/man
export MANPATH
fi
I think I finally know what is going on. This might also be the issue with the Windows installation. Your RAYPATH is missing a “.” (without quotes). The dot is essential as it tells Radiance binaries to look for cal files, modifier files etc in the local directory too.
Let me see if I can recreate this error with the RAYPATH being that way.
The export statements that I use are below (this is from my .bashrc). The colons append the paths together. You can put this right at the beginning of your bash file like Mostapha does for windows. The advantage of doing so would be that you can rest assured that the first directory looked up for binary and auxiliary files will be the one that you specify locally.
export PATH=.:/home/sarith/apps/radiance/bin:$PATH
export RAYPATH=.:/home/sarith/apps/radiance/lib:$RAYPATH
export MANPATH=.:/home/sarith/apps/radiance/man:$MANPATH
If I run several cases at the same time, will Radiance accept that the same rcontrib function is being sollicited simultaneously?
Of course not elegant, but I had in mind to multiply the number of Radiance installations to as many CPUs I hold. Further, add those environment settings PATH,RAYPATH,MANPATH at the beginning of each commands.sh file.
@OlivierDambron Rcontrib can be called any number of times simultaneously, however, a better solution would be using the -n flag directly in rcontrib. I did some large simulations a few months ago and found that the bottleneck is usually around matrix multiplication than actual raytracing (which is where dctimestep and rmtxop come into the picture).
I’ve just run a grid based DC simulation of about 32 000 points on the cloud using a Windows server with 16 CPUs. I’ve decomposed the test points into 16 cases that I executed using a batch command file. All completed within 30 minutes.
I am unable to sort the .ill files of each case and merge them before reading the results back using the Honeybee Read annual results component, the format seems to be problematic. This would be useful instead of reloading the case 16 times to obtain the analysis grid.
I dont (want to) know much Grasshopper and dont really understand how the whole datatree thing works in it. So I worked with a single points file and ran a dummy calculation with all the 100K points (ab 0, dark sky). Then I split the calculations outside of Gh through a process similar to yours and put the results back together into a single file. I replaced the dummy results file with the results file from actual calculations and was able to get the mesh visualizations to work. There was a fair amount of trial and error, and lots of Python coding involved. Unfortunately, the code is somewhere on computer inside HKS offices in Dallas (and also perhaps on their private repository).
Anyway this need not be so complicated and I think this will be recurring issue as more people start pushing the library to its limits. I am pretty sure that there are better solutions around… @mostapha?
I can only say that I have been working on this but never fully finished it to push it to Github.
@OlivierDambron, why don’t you just use -n 16 instead of breaking down the file into 16 cases? Also with the current loading workflow Grasshopper will run out of memory if you load the results for 32K points.