I have used the new ladybug tools for processing a large hospital. All components are really much faster then with the legacy version. (promissing) Only the process of translating the data when sent to Openstudio, is really slow! (2 hours 1 core) Is there perhaps a more quick way to translate the data?
Wow! This is really a beautiful and impressive-sized model. 800 rooms!
I think you win for the biggest energy model that I have seen with the LBT plugin to date. Really well done!
The slowness of OpenStudio is something that has bothered me too and we have tried hard on our end to get down the run time of the translation process. But there are just things that we cannot change in the way that the OpenStudio SDK was put together that make it slow and poorly-suited to large models. I can offer two possible ways around the slowness:
If you are ok with only modeling heating/cooling loads and not the fully-detailed HVAC, you can use the direct-to-idf translators that are built into honeybee-energy. Because we wrote these translators well and the whole process is in Python (without having to go over to Ruby or deal with outputting both an OSM and an IDF), they should be an order of magnitude faster than the pathway through OpenStudio. At the moment, the only component that uses these direct-to-idf translators is the “HB Annual Loads” component but, if you want to try this out on your model these are the lines of code that are relevant to the translation process:
If you need the fully-detailed HVAC, then you really don’t have a choice except to use the OpenStudio pathway. However, the way that I would recommend simulating something like this is to model each story of the building as a separate Honeybee Model (or OSM). You can treat the interior ceilings and the floors as adiabatic and still use the Surface boundary condition for the adjacent walls within one story. That way, you can capture the heat flow in between core/perimeter, which I have usually found is a bit more important than the heat flow from floor-to-floor. Using the “HB Rooms by Floor Height”, I see that there are ~23 stories that you can break your building into and running 23 translation/simulation processes in parallel is going to be MUCH faster than trying to simulate it all with one model.
FYI, for option 2, I would really recommend that you set up a model like this as a Dragonfly Model using the Rooms-to-Stories-to-Building method like you see in this sample file. If you set up your model this way, you will see that the latest Dragonfly has an option to export each Story of the model as a separate Honeybee model (and include the rest of the surrounding stories as context shade in each model). So this should really streamline your process of parallelization. If you want to add all of the detailed window and balcony geometries you can do so to the Honeybee models after they have been translated from Dragonfly. But another approach to speed things up would be to just model the windows with a simple window ratio, which is usually fine for simulating building energy use (though you’ll need the detailed geometry for daylight or thermal comfort mapping).
Thank you for the information, but reading your comment I immediatly noticed something in the model was wrong. The model should contain 200 rooms instead of 800. Although not having anymore the honour of having build the largest Honeybee Model I am realy happy you found the problem. This is what is causing the enormous computation time.
In answer to your suggestions:
We just want to generate the heating loads but as EnergyPlus calculates these loads in a very particular way (heat recovery is not taken into account) we have decided to use the peak rates generated by the fully detailed HVAC modelling.
This workflow could be nice. I only notice there is quite a difference in results comparing with a whole building simulation.
But since I changed the 800 rooms to 200 rooms the simulation runs fine! I think Just half an hour!
Well, that just goes to show that you built a model at a scale that I can’t tell the number of rooms just by looking at it . Even if it has a quarter of the rooms I thought it had, it’s still beautiful and it’s at a level of detail that I have not seen for model of that size. So you definitely retain some honor!
I any case, I realize that the original question might be moot but, in the event that you make an even larger model in the future, I can offer the following advice:
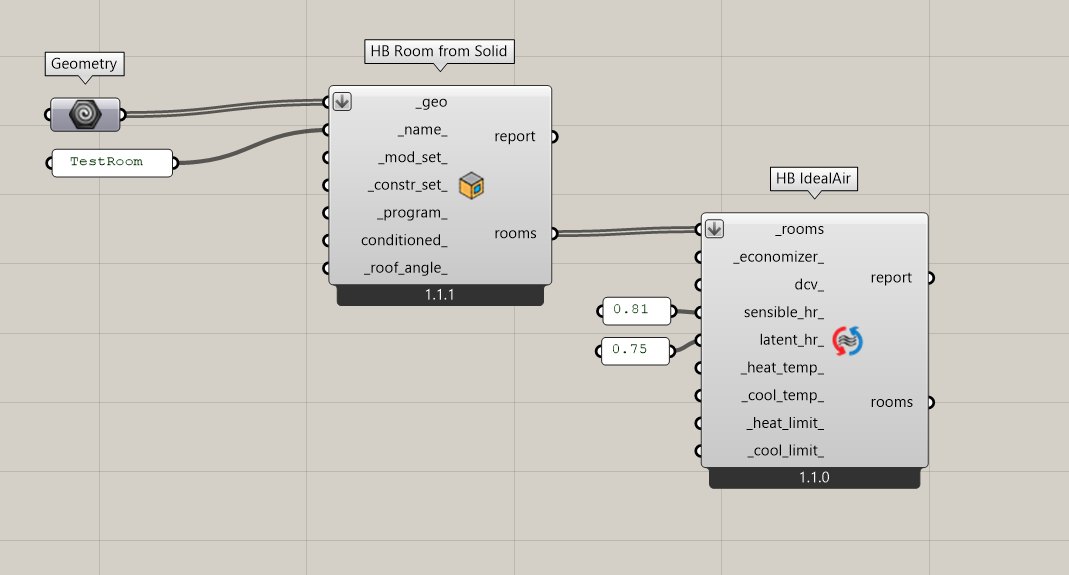
The direct-to-idf method should be useful as long as you need the heating loads on a room-by-room basis. You can account for heat recovery by assigning a custom ideal air system to the rooms using the “HB IdealAir” component like you see below. But I understand that, if you are trying to model the heating load at some point in a central air loop, you will need a detailed HVAC to figure that out.
I didn’t realize that your focus was primarily on peak loads and I can see how splitting up the model into separate stories could make things difficult, especially for figuring out the size plant equipment or of air loops supplying several stories. But, for annual energy use, I haven’t been able to find a case yet where the EUI that I get from modeling each story separately is more than 1% different than the EUI of modeling it all together. That is, as long as I account for the building’s self-shading by modeling the other stories as context shade in each story honeybee model. If there are cases that you have found where results differ a lot between the two ways of modeling, it would be helpful to know about them.
As I want to run the Ideal Airloads version standard as well, using the idf method is a good advise. Thanks!
I do not have tried the seperate floor method yet. I only used a comparable method for an appartment building, in which I simulated 8 different apartments one after each other in order to get the heating loads of each apartment. To get the right results I had to assume that the neighbouring appartments in winter had a temperature of 15 [C] (dutch regulations). First I ran the the simulation with the adiabatic trick. For the second run I joined the rooms of the surrounding apartments and set the temperature of these apartments to 15 [C] and ran the simulation adding a seperate HVAC system to the apartment of interest. This made quite a difference. But I agree for the overall energy use the difference will be very small. However it would be nice if with the introduction of Polination also the “Other Side Coefficients” can be aplied to constructions. Then it would be possible to run a whole appartment complex in one batch for getting all the heating loads.
Thanks for the explanation and I understand better why you have been asking for the “Other Side Coefficients”. You’re right that they could be really helpful in cases where we want to break up models for parallelization. In honesty, the only reason why I have not addressed the issue here yet is that I have been prioritizing getting the last missing legacy features into LBT. But I’m getting close to the end of this list. I’ll put the Other Side Coefficients at the top of the list for things to implement after I have hit the end of the “Legacy to LBT” checklist.
For this problem, I use a direct command line form to convert Hb Model in HBJson format directly to IDF file, which can be detached from the time-consuming translation process in Openstudio. This approach should be easily doable in Rhino8.
hi,@LuizHVAC
I thought you were supposed to be replying to me.If you’re expecting to do this using Python Script in Rhino8, I suggest you refer directly to the Ladybug Tools SDK, for example here
You can go through the following steps:
1.Locate the Rhino Code folder, usually it should be in the path C:\Users\[UserName]\.rhinocode\py39-rh8
Type python.exe -m pip install honeybee_energy in cmd to install the hoenyebe_energy related python libraries
2.In Rhino8, write a script based on the Ladybug Tools SDK and execute it.Like this example.
import os
from ladybug.futil import write_to_file
from honeybee.model import Model
from honeybee.room import Room
from honeybee.config import folders
from honeybee_energy.lib.programtypes import office_program
from honeybee_energy.hvac.idealair import IdealAirSystem
from honeybee_energy.simulation.parameter import SimulationParameter
# Get input Model
room = Room.from_box('Tiny House Zone', 5, 10, 3)
room.properties.energy.program_type = office_program
room.properties.energy.add_default_ideal_air()
model = Model('Tiny House', [room])
# Get the input SimulationParameter
sim_par = SimulationParameter()
sim_par.output.add_zone_energy_use()
ddy_file = 'C:/EnergyPlusV9-0-1/WeatherData/USA_CO_Golden-NREL.724666_TMY3.ddy'
sim_par.sizing_parameter.add_from_ddy_996_004(ddy_file)
# create the IDF string for simulation parameters and model
idf_str = '\n\n'.join((sim_par.to_idf(), model.to.idf(model)))
# write the final string into an IDF
idf = os.path.join(folders.default_simulation_folder, 'test_file', 'in.idf')
write_to_file(idf, idf_str, True)
Finally, this is only an example. In practice I actually create a large number of hbjson model files and then convert them via the CLI tool.
import os
import subprocess
hbjson_folder = r'D:\Desktop\load_hbjson'
output_folder = r'D:\Desktop\make_idf'
sim_par_json = r'D:\Desktop\make_idf\sim_par_json.json'
os.makedirs(output_folder, exist_ok=True)
hbjson_files = [f for f in os.listdir(hbjson_folder) if f.endswith('.hbjson')]
for hbjson_file in hbjson_files:
full_path = os.path.join(hbjson_folder, hbjson_file)
output_path = os.path.join(output_folder, os.path.splitext(hbjson_file)[0] + '.idf')
command = [
'honeybee-energy', 'translate', 'model-to-idf',
'--sim-par-json', sim_par_json,
'--output-file', output_path,
full_path
]
subprocess.run(command, check=True)
 . Even if it has a quarter of the rooms I thought it had, it’s still beautiful and it’s at a level of detail that I have not seen for model of that size. So you definitely retain some honor!
. Even if it has a quarter of the rooms I thought it had, it’s still beautiful and it’s at a level of detail that I have not seen for model of that size. So you definitely retain some honor!