Hi everyone,
I would like to cross-validate my experimental illuminance measurements with the results from the “HB Annual Daylight” recipe (or vice versa).
To achieve this, I am currently considering the following workflow:
-
Take my measurement data (containing the columns
date_st (as standard time),dni, anddhi) and interpolate/resample it into exactly 8760 rows using a custom Python function (convertTo8760). -
Generate a custom EPW file from this resampled dataframe using another custom function (
writeEPW). -
Import this custom EPW into Honeybee and run the HB Annual Daylight simulation.
I have a few questions regarding this approach:
-
What do you think of this workflow? Has anyone done something similar?
-
How does HB-Radiance handle time internally? Will it correctly calculate the solar angles (zenith, azimuth) and extraterrestrial normal irradiance based on my custom timestamps (
date_st) combined with the location data (lat,lon,tz,elv)? Is standard time the right one? How can seconds be handled? Or does the Annual Daylight recipe strictly assume standard hourly steps from Jan 1st 01:00 to Dec 31st 24:00, regardless of the custom timestamps provided in the EPW? -
Do I need further columns despite ‘date_st’, ‘dni’, ‘dhi’ to successfully conduct the HB-radiance simulations such as the three-hourly surface dew point temperature within the Perez luminous efficacy models, cmp.
-
Can simulations be done without it, with the classical assumtion W=2?
-
What do you think of the demo Python code I put together (with the help of AI) to handle the 8760 conversion and EPW writing?
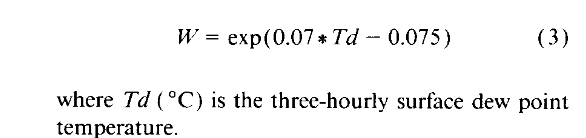
Thanks for your feedback and have a nice start to the week.
Simon
Here comes the code:
def writeEPW(
fnAbs: str,
df: pd.DataFrame,
lat: float,
lon: float,
tz: float,
elv: float
):
“”"
Writes a pandas DataFrame to a strictly compliant EnergyPlus Weather (EPW) file.
Matches the official EnergyPlus Data Dictionary (IDD).
Required columns in df: 'date_st', 'dni', 'dhi'
Optional columns (pvlib naming): 'ghi', 'temp_air', 'temp_dew', 'relative_humidity',
'atmospheric_pressure', 'wind_speed', 'wind_direction', etc.
"""
# 1. Validate mandatory columns
required_cols = ['date_st', 'dni', 'dhi']
missing_cols = [col for col in required_cols if col not in df.columns]
if missing_cols:
raise ValueError(f"Missing required columns in DataFrame: {missing_cols}")
df_epw = df.copy()
# 2. Handle EPW Time Convention (Hours run from 1 to 24)
df_epw['date_st'] = pd.to_datetime(df_epw['date_st'])
shifted_time = df_epw['date_st'] - pd.Timedelta(hours=1)
# Checks on leap year
has_leap_day = ((shifted_time.dt.month == 2) & (shifted_time.dt.day == 29)).any()
leap_flag = "Yes" if has_leap_day else "No"
# 3. Prepare the output DataFrame with exactly 35 columns
out_df = pd.DataFrame(index=df_epw.index)
# Columns 0-4: Date and Time
out_df[0] = shifted_time.dt.year
out_df[1] = shifted_time.dt.month
out_df[2] = shifted_time.dt.day
out_df[3] = shifted_time.dt.hour + 1
out_df[4] = 60 # Minute (Standard for hourly EPW data)
# Column 5: Data Source and Uncertainty Flags
out_df[5] = "?9?9?9?9?9?9?9?9?9?9?9?9?9?9?9?9?9?9?9?9?9?9?9?9?9*0"
# 4. Define official EPW missing values based on the EnergyPlus Data Dictionary
epw_defaults = {
6: 99.9, # temp_air (C)
7: 99.9, # temp_dew (C)
8: 999., # relative_humidity (%)
9: 999999., # atmospheric_pressure (Pa)
10: 9999., # etr (Wh/m2)
11: 9999., # etrn (Wh/m2)
12: 9999., # ghi_infrared (Wh/m2)
13: 9999., # ghi (Wh/m2)
14: 9999., # dni (Wh/m2) -> Will be overwritten
15: 9999., # dhi (Wh/m2) -> Will be overwritten
16: 999999., # global_hor_illum (lux)
17: 999999., # direct_normal_illum (lux)
18: 999999., # diffuse_horizontal_illum (lux)
19: 9999., # zenith_luminance (Cd/m2)
20: 999., # wind_direction (deg)
21: 999., # wind_speed (m/s)
22: 99, # total_sky_cover (tenths) -> INT
23: 99, # opaque_sky_cover (tenths) -> INT
24: 9999., # visibility (km)
25: 99999., # ceiling_height (m)
26: 9, # present_weather_observation -> INT
27: 999999999, # present_weather_codes -> INT
28: 999., # precipitable_water (mm)
29: 0.999, # aerosol_optical_depth (IDD specifies .999)
30: 999, # snow_depth (cm) -> INT
31: 99, # days_since_last_snowfall -> INT
32: 999., # albedo
33: 999., # liquid_precipitation_depth (mm)
34: 99 # liquid_precipitation_quantity (hr) -> INT
}
# Fill with missing values first
for col_idx, default_val in epw_defaults.items():
out_df[col_idx] = default_val
# 5. Overwrite defaults with actual data
col_mapping = {
'temp_air': 6, 'temp_dew': 7, 'relative_humidity': 8,
'atmospheric_pressure': 9, 'etr': 10, 'etrn': 11,
'ghi_infrared': 12, 'ghi': 13, 'dni': 14, 'dhi': 15,
'wind_direction': 20, 'wind_speed': 21, 'albedo': 32
}
for col_name, epw_idx in col_mapping.items():
if col_name in df_epw.columns:
out_df[epw_idx] = df_epw[col_name].round(3)
# 6. Enforce specific integer types required by EnergyPlus IDD
int_columns = [0, 1, 2, 3, 4, 22, 23, 26, 27, 30, 31, 34]
for c in int_columns:
out_df[c] = out_df[c].astype(int)
# 7. Generate simplified EPW Header (incorporating dynamic leap_flag)
header_lines = [
f"LOCATION,TestBed,-,-,Python_Script,999,{lat},{lon},{tz},{elv}\n",
"DESIGN CONDITIONS,0\n",
"TYPICAL/EXTREME PERIODS,0\n",
"GROUND TEMPERATURES,0\n",
f"HOLIDAYS/DAYLIGHT SAVINGS,{leap_flag},0,0,0\n",
"COMMENTS 1,Generated via Python Script (IDD strictly compliant)\n",
"COMMENTS 2,\n",
"DATA PERIODS,1,1,Data,Sunday,1/1,12/31\n"
]
# 8. Create directory if it doesn't exist and write to file
dir_name = os.path.dirname(fnAbs)
if dir_name:
os.makedirs(dir_name, exist_ok=True)
with open(fnAbs, 'w', encoding='utf-8') as f:
f.writelines(header_lines)
# Append the pandas dataframe to the file (No headers, no index)
out_df.to_csv(fnAbs, mode='a', header=False, index=False, encoding='utf-8', lineterminator='\n')
def convertTo8760(dfIn: pd.DataFrame) → pd.DataFrame:
“”"
Takes a dataframe of any time length (e.g., a 3-day measurement) and resamples
it into exactly 8760 rows. The start_time and end_time are strictly preserved
from the original data. The delta-time is automatically calculated to fit
exactly 8760 evenly spaced rows between start and end.
Missing or new intermediate values are time-interpolated.
:param dfIn: Input DataFrame containing a 'date_st' column.
:return: DataFrame with exactly 8760 rows.
"""
# 1. Create a copy and set the datetime index
df = dfIn.copy()
if 'date_st' not in df.columns:
raise ValueError("The DataFrame must contain a 'date_st' column.")
df['date_st'] = pd.to_datetime(df['date_st'])
df.set_index('date_st', inplace=True)
# Sort index and remove duplicates just to be safe
df.sort_index(inplace=True)
df = df[~df.index.duplicated(keep='first')]
# 2. Extract the exact start and end times from the original data
start_time = df.index.min()
end_time = df.index.max()
# 3. Generate exactly 8760 evenly spaced timestamps between start and end
# Pandas will automatically calculate the required delta-time to fit 8760 periods.
target_index = pd.date_range(start=start_time, end=end_time, periods=8760)
# 4. To interpolate accurately, we combine the original timestamps with the new ones.
# This ensures the original anchor values are present for the math calculation.
combined_index = df.index.union(target_index).drop_duplicates().sort_values()
df_combined = df.reindex(combined_index)
# 5. Interpolate the missing values based on exact time distances
df_combined = df_combined.interpolate(method='time')
# 6. Extract ONLY the 8760 target timestamps
df_8760 = df_combined.loc[target_index].copy()
# 7. Edge-case handling (Forward/Backward fill in case of extreme edge NaNs)
df_8760 = df_8760.bfill().ffill()
# 8. Reset the index so 'date_st' is a normal column again
df_8760.index.name = 'date_st'
df_8760.reset_index(inplace=True)
# Final validation
assert len(df_8760) == 8760, f"Error: Result has {len(df_8760)} rows, expected 8760."
return df_8760