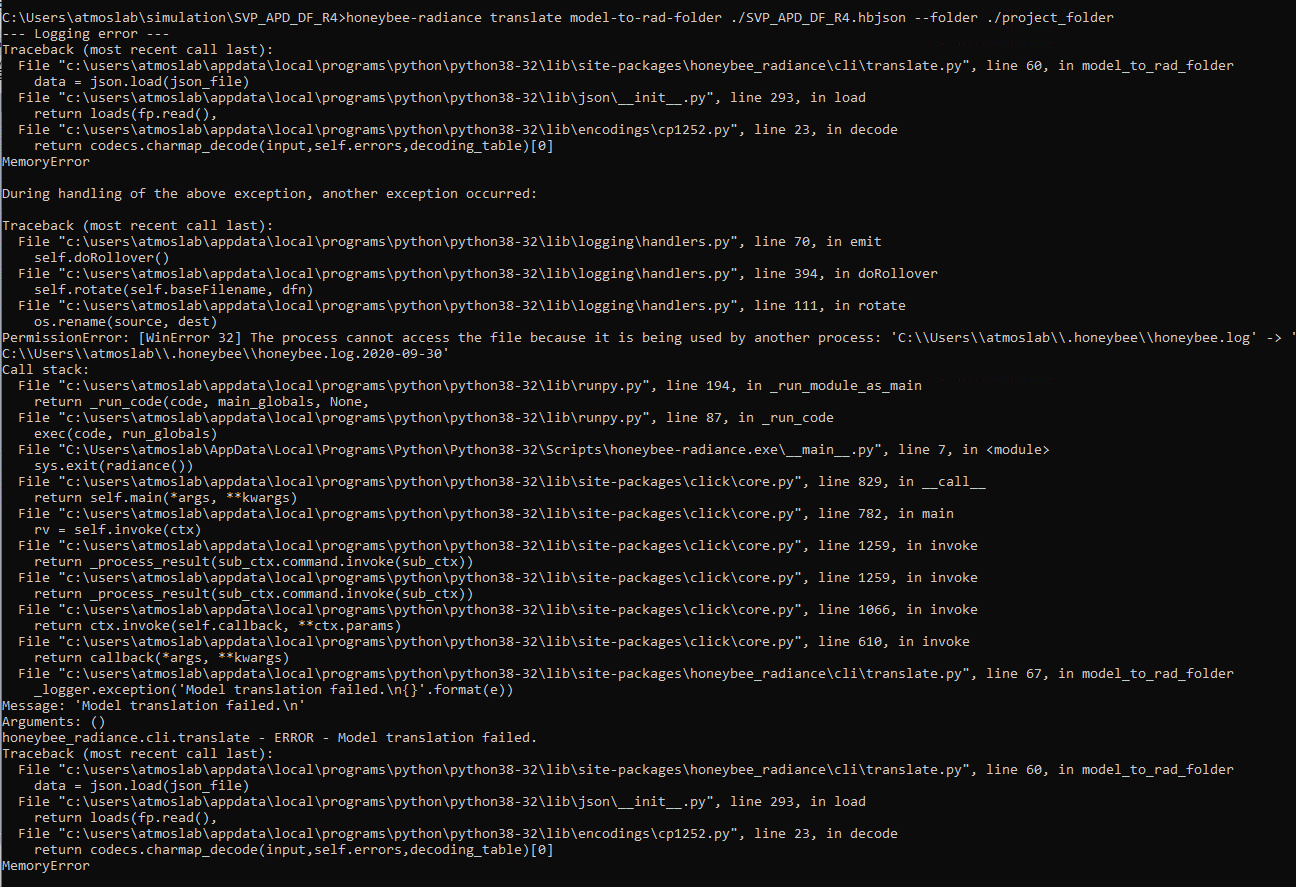
I ran into some memory errors with HB-R to execute a DF recipe on a big model (heavy meshes) with a hbjson that weighs 850 MB.
Are there any limitations to bear in mind with the current workflow? otherwise I’ll just go for simplifying the model much more.
Nice one! I love it when people break stuff. This seems to be an issue for loading the HBJSON file as a model in the first place which shouldn’t happen. To test it in isolation try something like this.
from honeybee.model import Model
import json
import pathlib
fp = r"PATH-TO-HBJSON-FILE"
input_file = pathlib.Path(fp)
model_dict = json.loads(input_file.read_text())
model = Model.from_dict(model_dict)
If this fails then please send us a link where we can download and test the file on our side. You know where to find us!
Also it looks like you are using Python 3.8 - Luigi which is what we use to execute the recipes is not compatible with Python 3.8. Can you try with Python 3.7?
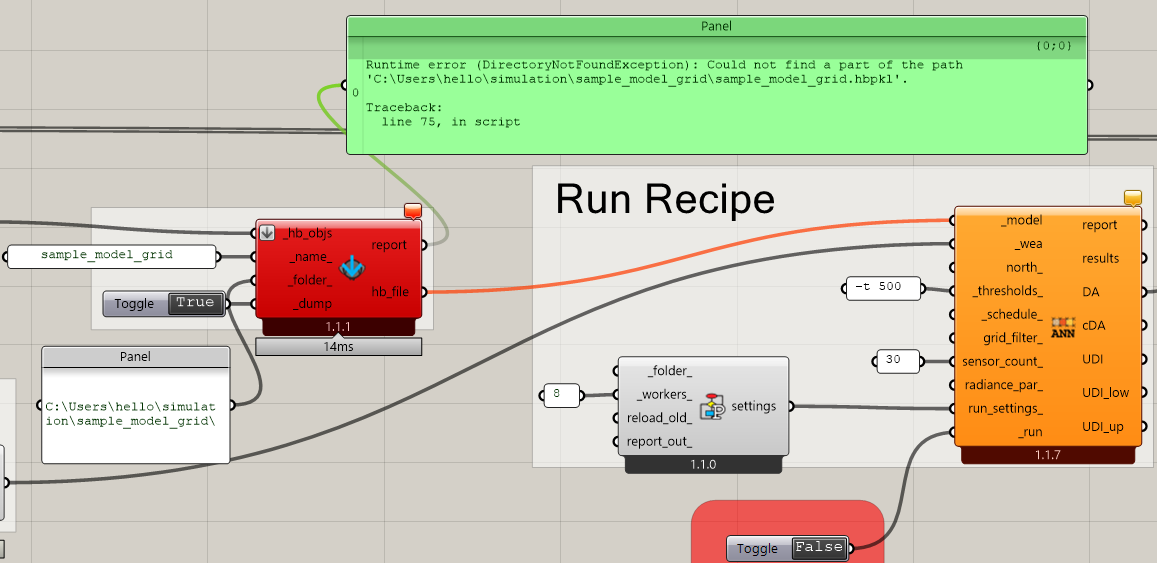
I managed to run the models by breaking them down into smaller parts. There seems to be some memory limits either from Radiance, Python or hardware. @sarith I wonder if you’ve ever encountered memory errors when running large models through the command line.
Hi @OlivierDambron, yup that has happened many times. Usually if the model is too complicated the octree generation process might run into memory issues, or in the case of annual simulations if the number of grid points are too many, matrix multiplication runs into similar issues.
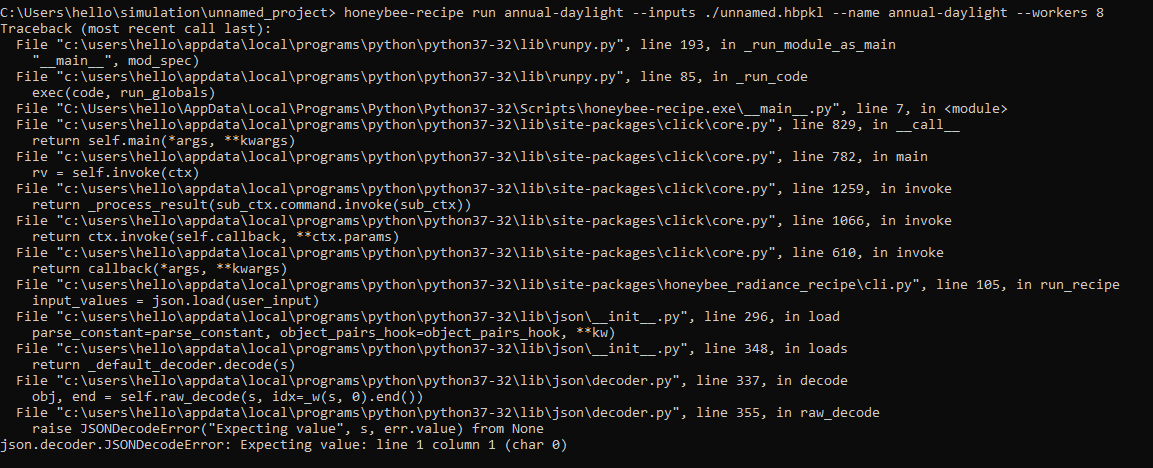
But based on your screenshot, it appears that the error is occurring upstream at a Python level (“translation failed”).
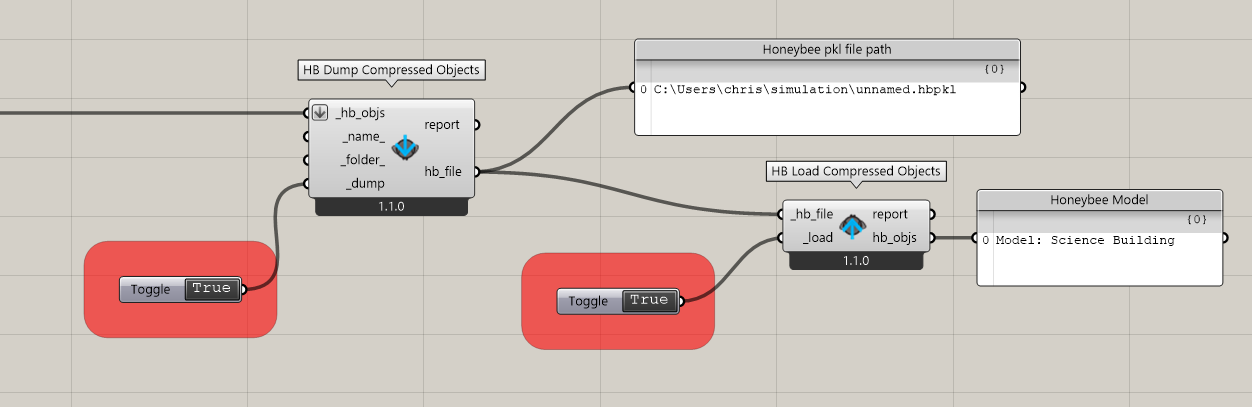
So I have two new components for you to test to see if they solve your issue. They are called “HB Dump Compressed Objects” and the “HB Load Compressed Objects.” They work just like the JSON-serializing components except they use pkl files instead of json:
You should see that the pkl file size is at least ~1/3 smaller and, most importantly, the serialization process should hopefully not max out your memory.
You can get the new components by running the “LB Versioner” component. I would test them myself but it seems the link you posted is broken. If you can test them on your end and let us know if it works, we’ll consider making the commands accept .hbpkl file inputs just as they accept .hbjson file inputs. Then, you should be able to run them through recipes without issues.
Sorry for the broken link, I think I overwrote the file while rushing.
I went for simplifying drastically the model instead of a “select all/assign/run”.
Perhaps it is worth mentioning that the geometry I was trying to use was extracted from an IFC file (using geogym plugins). Many items behaved very strangely with the HB components:
sometimes nurbs or meshes would return the components orange/red due to invalid breps or attempts to divide by 0.
sometimes a simple gh transformation to those geometries would make the HB Face accept it.
when these went through the HB Face components, often the HB Visualize wasn’t showing coherent geometries with that through the Spider Rad Viewer. Although this is a different issue, I just thought I’d mention it as all of the fuss I made could very well be due to inappropriate geometry extracted from an IFC file.
The two hbpkl components work on my end. Thank you, this will definitely help with heavy cases.
I look forward to the commands accepting hbpkl it.
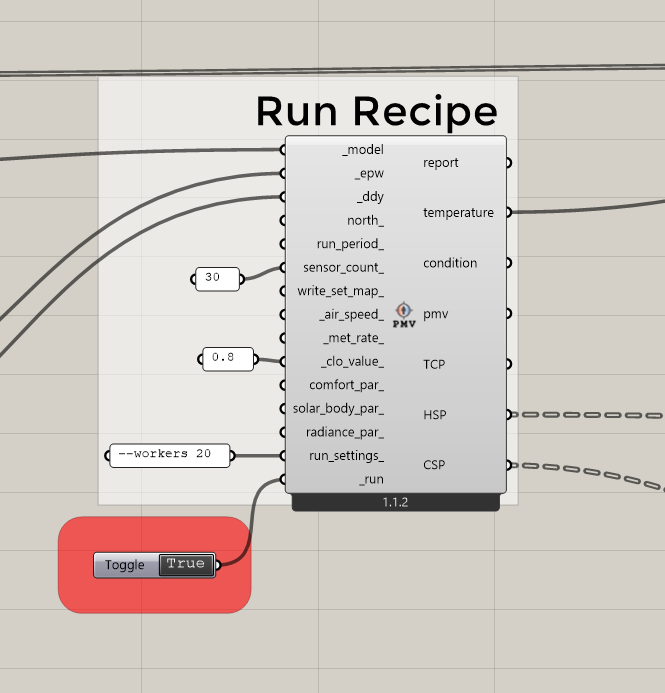
As a side note, I noticed after updating that the HB Run Recipe component disappeared from the ghtab:
I have to imagine that, with that much geometry, you would naturally have a lot of invalid objects. I would guess that the “attempts to divide by 0” come from breps or mesh faces that have 0 area and are not considered valid. Usually, there are ways to filter out these invalid objects with native GH components and it sounds like that’s what you have done here.
If you are wondering whether you should trust the HB Visualize vs. the Spider Rad viewer, the HB Visualize component is probably the one with better fidelity to what is actually “seen” by Radiance. We identified a few bugs in the Rad viewer related to vertex ordering and I would bet that some of your cases of invalid geometry might not display as the invalid objects that they are in the rad viewer. Of course, the best approach will be to do an image-based Radiance simulation, which we will hopefully have for you soon.
Now that we know your model can be serialized to a .pkl file correctly, I think the first step is that we will add support in the model-to-rad-folder command to accept either a HBJSON or a HBpkl file. Then, you should be able to run all radiance recipes with a .pkl file that will not max out your memory.
I think we will still want HBJSON to be the default and the “gold standard” to transfer Honeybee models given that JSON is cross-language while pkl is a Python thing. And this cross-language capability is needed for many parts of the software, including the ability to use OpenStudio’s Ruby bindings and the C# interfaces that are in the works for Revit and Rhino. But, just for radiance recipes in the Grasshopper plugin, we can add support to connect up a path to the .pkl file instead of the model object itself. I’ll try to implement this today and let you know when it’s ready to test.
And, yes, regarding the recipes, we made a big change recently that has gotten rid of the “HB Run Recipe” component. Now the recipe components themselves contain everything that is needed to run them (including a _run boolean toggle). We did this primarily so that we can expose different types of outputs for different recipes (instead of expecting all recipes to have a single “results” output). @mostapha has been using the new capability to include post-processing within the annual daylight recipe, meaning that there will soon be outputs of DA and UDI on the annual daylight recipe itself. This should make things more streamlined when people aren’t interested in computing annual metrics with a range of occupancy schedules or illuminance thresholds. I have also been using the capability on the first draft of the comfort-mapping recipes to expose Thermal Comfort Percent (TCP), Heat Sensation Percent (HSP) and Cold Sensation Percent (CSP):
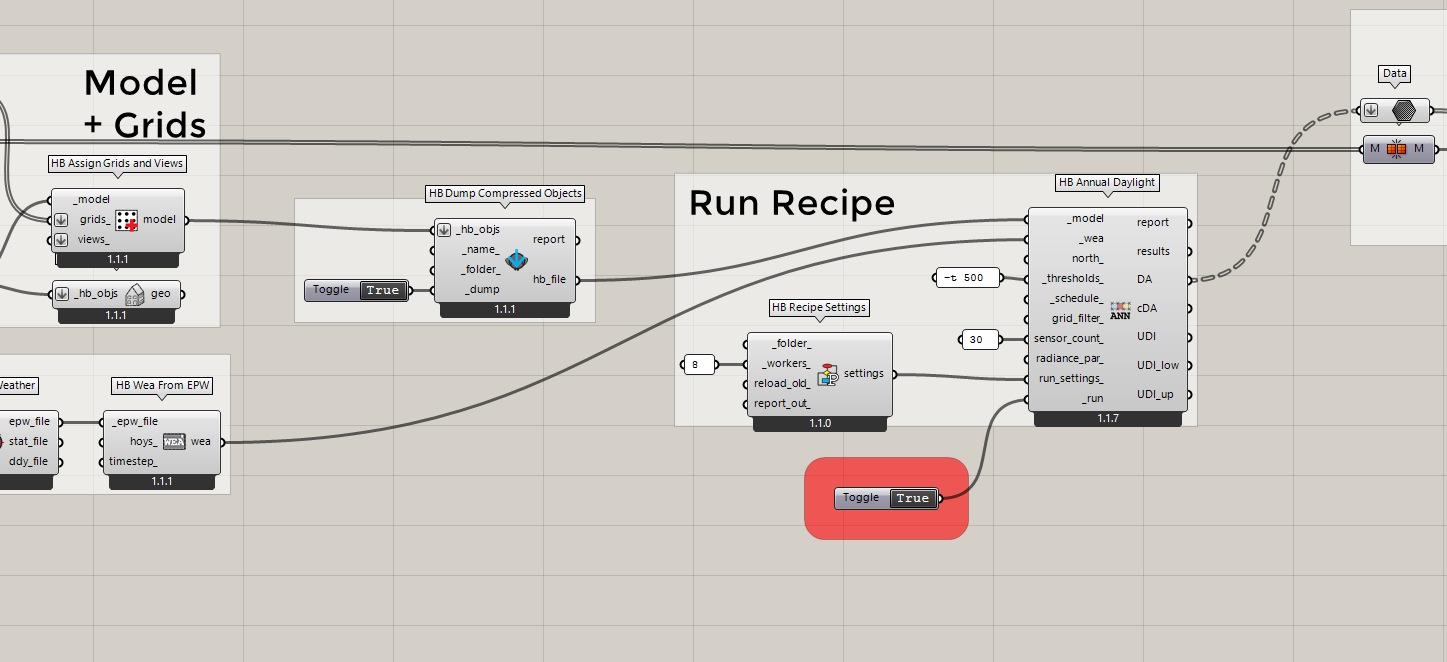
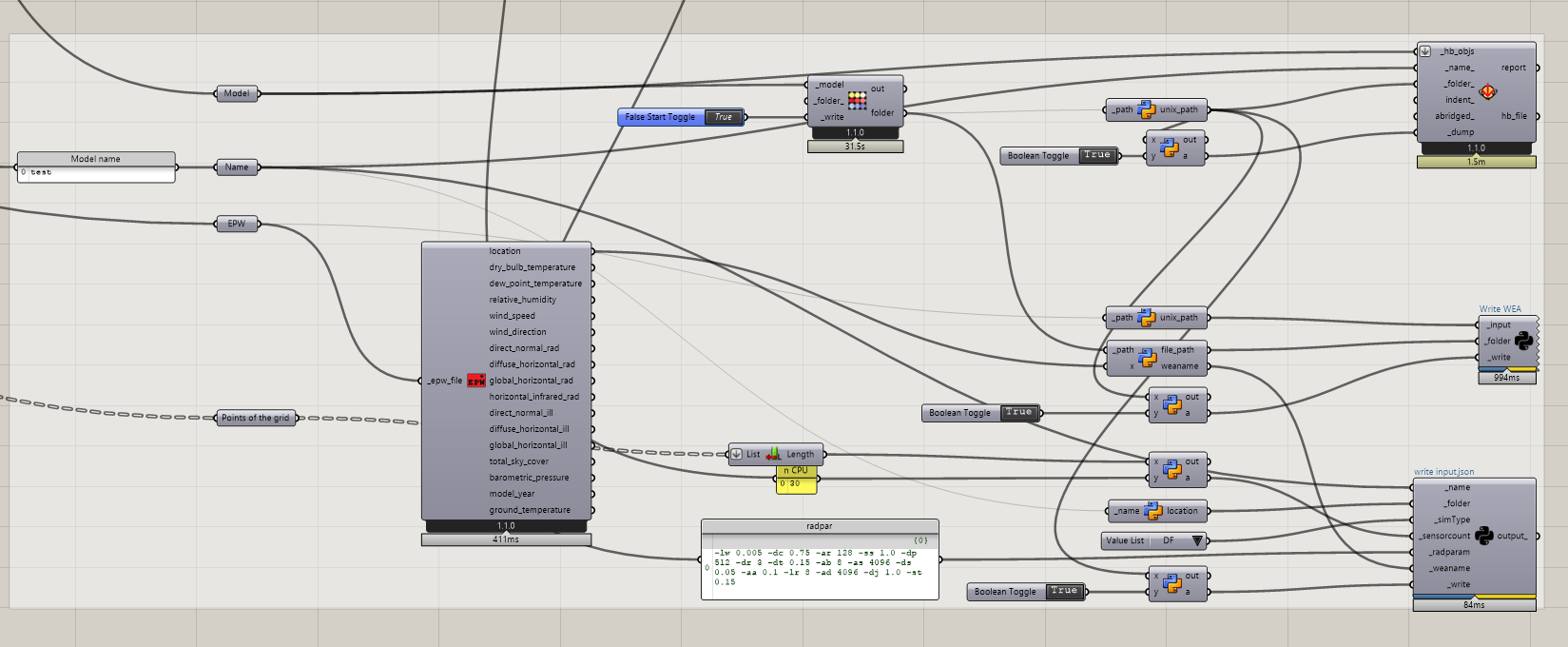
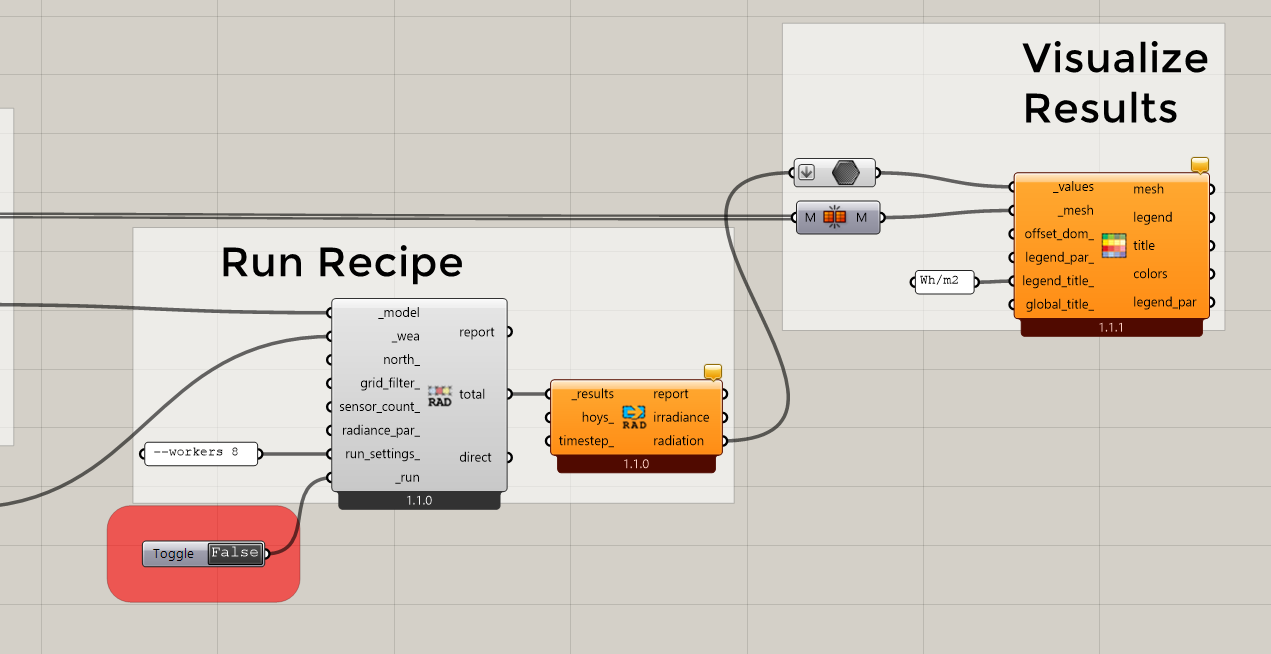
If you run the “LB Versioner” to get the latest development version of the plugin, you can now connect up a .pkl file directly to the radiance recipes like so:
If you connect the model this way instead of connecting it directly to the recipe, all of the serialization process will stay in the .pkl world and you shouldn’t have any of the memory-overload issues you experienced with JSON. Let us know if you get the chance to test it with your large model and here is a sample file to show you the workflow:
Hi @chris , thanks so much for accomodating these functions.
The pkl dump component works well on grasshopper. I tested the heavy model and it went through, reducing those 20-30% in weight is significant. Here are a couple of things I noticed:
the simulation runs well with the unnamed_project set by default. However specifying a name for the dumped pkl file and running the case, doesn’t recreate the corresponding folder.
Finally, do you think it would be possible to integrate a “_write” input in the recipe component? This way, we’ll be able to execute multiple cases at the same time. So far I’ve gone around it to write my cases (dump json, write wea, write inputs.json) on the side and do simultaneous runs through the command line.
oh I forgot one more question:
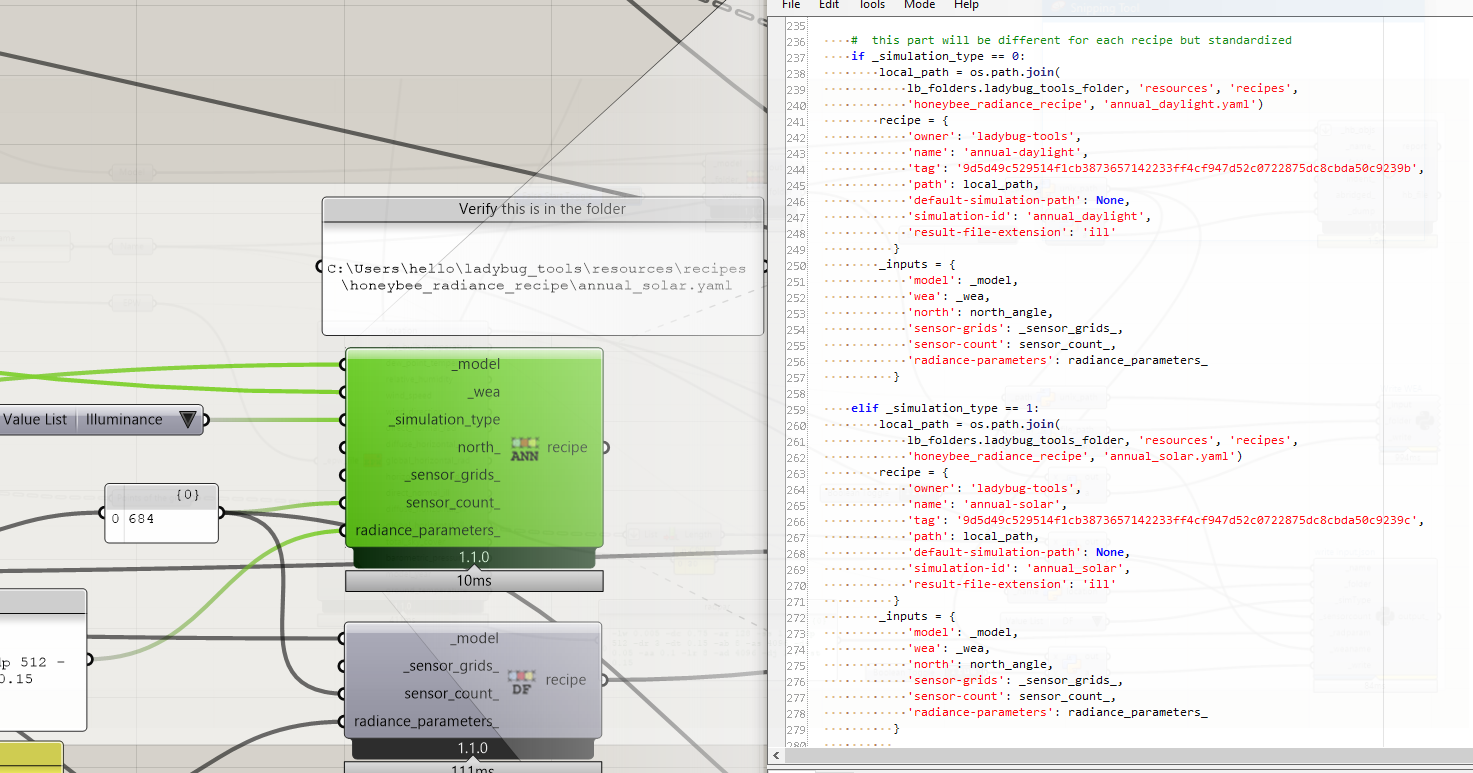
in the previous version I had tweaked the run recipe component with an input for simulation type. I had copied the .yaml file in the python directories and re-adapted it so as to calculate irradiance.
Thanks for testing @OlivierDambron . Let me go down the list of questions:
Good catch. I see that we were also missing the folder creation on the component that dumps to JSON. I will add the folder creation quickly now.
That’s because the command is no longer called honeybee-recipe run. Now, it is called queenbee local run and you can get the queenbee-local package and everything that you need to run recipes locally by using pip install lbt-recipes.
I would rather not add an extra component input for this (if it ends up being a huge pain point, maybe we can add it as an option for the “HB Recipe Settings”). But, in any case, you can get exactly what you want on the Ladybug Tools SDK layer. All of the recipes are now represented via a single class with attributes that can be set and methods for different steps of the execution process. There’s a method for write_inputs_json, which you can call to automatically run the handlers on the inputs and write all input files to the project folder. So just replace recipe.run() with recipe.write_inputs_json() and you should be good.
Yes, we already have an annual radiation recipe component in the development version:
Let us know if there are certain outputs that you would want exposed other than the raw .ill files that need to be processed with that extra component there.
For point 2., we have put back a CLI that is just for running the recipes that we ship with the Ladybug Tools Grasshopper plugin. The new package is called lbt-recipes and you can see that we added some info about it to the core SDK docs:
queenbee local may become something different than it is now depending on how we develop support for private recipes on Pollination. But, for the long term, you should be able to use the lbt-recipes package to run the recipes that we ship with Ladybug Tools Grasshopper plugin from command line.
To come back on this topic of writing and running multiple case at the same time,
I’ve updated all to latest version and was able to write cases effectively as per your instructions above.
Using command prompt, I navigate into the simulation folder and when I execute :
“queenbee local run annual_daylight -i annual_daylight_inputs.json --workers 7”
Technically, you can also run it will queenbee-local but you need to give the full path to the recipe folder instead of the recipe name. In any event, using lbt-recipes is the official way to do it.